Memory Augmented Neural Networks for Retrieval and Continual Learning
In January 2026, DeepSeek released Engram, a new sparse memory module that enables knowledge look-up within the forward pass.
Engram's module splits where memory is stored from where reasoning happens, analogous to Mixture of Experts, which made monolithic transformers capable of conditional computation by splitting which parameters handle which tokens. It increases architectural capacity without spending FLOPs and ensures models don’t waste sequential compute storing static facts. It opened up a "new axis of sparsity" for foundation models, but perhaps more importantly, it resurrected a dormant line of architectures known as Memory Augmented Neural Networks.
Memory Augmented Networks are not new – they date back to 2014 – but I believe that their modern counterparts could open new axes for agents. They may offer the ability to intrinsically perform retrieval by reading over a parameterized memory instead of context alone, and perform weight updates by writing new information to themselves without catastrophic forgetting in the forward pass.
In this blog, we’ll review how we approach retrieval and test-time training today, and then take a trip down memory lane to explore how Memory Networks, Neural Turing Machines and several more architectures of old may inspire a new generation that scales foundational agents along these dimensions.
Retrieval
Semantic and Episodic Memory
After the launch of GPT-3 and Patrick Lewis et al.'s work on RAG, most LLM workflows followed a simple pattern. You wrote a prompt, semantic-searched over a vector database, and dropped embedded chunks similar to the query into context.
Over the last few years, semantic memory has grown. Document corpora now span entire legal and medical databases, and episodic memory of previous agent traces have ballooned. Both types of memory are useful for retrieval, which itself has grown in complexity both by adding steps like reranking and increasingly using multi-vector approaches: instead of compressing documents and queries to single vectors, we embed each document and query token individually and check how maximally similar they are to each other before summing the results.
However, the growth of information in context windows has led to higher inference costs, and in some cases causes context rot as models struggle to retrieve or prioritize specific information in long context. Moreover, for multi-hop reasoning, the model must split a query into multiple steps of retrieval across disparate locations, increasing response latency. While we can post-train models to efficiently perform these searches across filesystems and vector databases, the tokens from tool calls themselves also fill up context and lead to higher cost.
Ideally we can reduce these costs and latency, and today, there are several such approaches operating in activation or token space.
Context Compaction and Meta-Harnesses
In token space, we can train an LLM to summarize retrieved context at inference time given a specific query. Relevant facts would be retained and sequence length would shrink.
Recently, a more interesting line of work called context compaction opened in activation space that shrinks the size of the KV cache. Cartridges by Eyuboglu et al., found that if you treat a small set of KV activations as free parameters and train them to match the performance of a model with a longer context on a specific set of questions with a self-study distillation objective, they reach similar results despite using significantly shorter sequence lengths. Fast KV Compaction via Attention Matching by Zweiger et al. even achieves similar compression roughly two orders of magnitude faster.
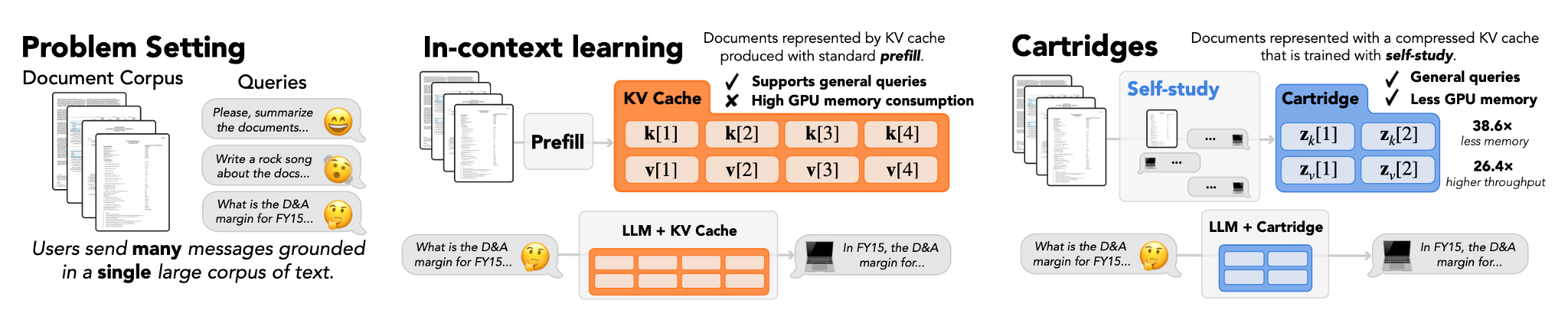
As query complexity grows and you require millions of facts from millions of documents in a multi-step reasoning process, we would soon need a meta-learned system for which cartridges to retrieve given the most recent agent observation. We would also need to meta-learn which cartridges to update at any given point given the arrival of a new document. Work like Meta-Harnesses by Lee et al. already explores how an agent system can better optimize its surrounding tool calls and retrieval, representing good groundwork for this type of system.
All of this is to say that there’s ample work going on along the token level and KV compaction axes. I am equally excited about another complementary axis which doesn’t require separate retrieved models and meta-learned systems, but makes the model itself capable of retrieval.
The New Axis: training retrieval into the model
Right now, we don’t think of retrieval as a process that is intrinsic to the model; RAG is explicitly framed as an external system that the model communicates with. But what if it wasn’t?
If retrieval was something trained into models, we wouldn’t waste tokens on tool calls, or have to train cartridges. External unchanging information could be encoded, compressed into parameter space as it arrives and cheaply, readily retrieved in the forward pass as a function of the model itself. The model will have itself meta-learned how to read its memory given a new query, and it would also be possible to add to the memory bank over time.
If this approach were to work, it would require a new architecture that stops treating the context window as the only substrate for memory. Fortunately, there is a rich architectural lineage that supports this type of research.
Weston, Borgeaud and Memory Matrices
We didn’t always think of “context” as the single entry point for all information in the model. While this has been the dominant worldview since the release of the transformer, in the preceding years there was no global consensus on how models should optimally retrieve information.
In 2014, soon after Bahdanau et al. published their work on attention while attempting to solve language translation, Weston et al. published Memory Networks, one of the earliest Memory Augmented Neural Networks that independently arrived at attention as the solution to an entirely different problem.
The authors were trying to solve question answering problems, and claimed the hidden state of RNNs were too small to encode information about the past since "knowledge is compressed into dense vectors." Unlike Bahdanau, who allowed a decoder to attend to an encoder's hidden states and thus treated memory implicitly as anything that was passed into the encoder, their big conceptual leap was to create an explicit, external, addressable memory matrix that the model queries during the forward pass with attention. The retrieved information would be concatenated with the original query and propagated to the following layer, repeating several times throughout the network.
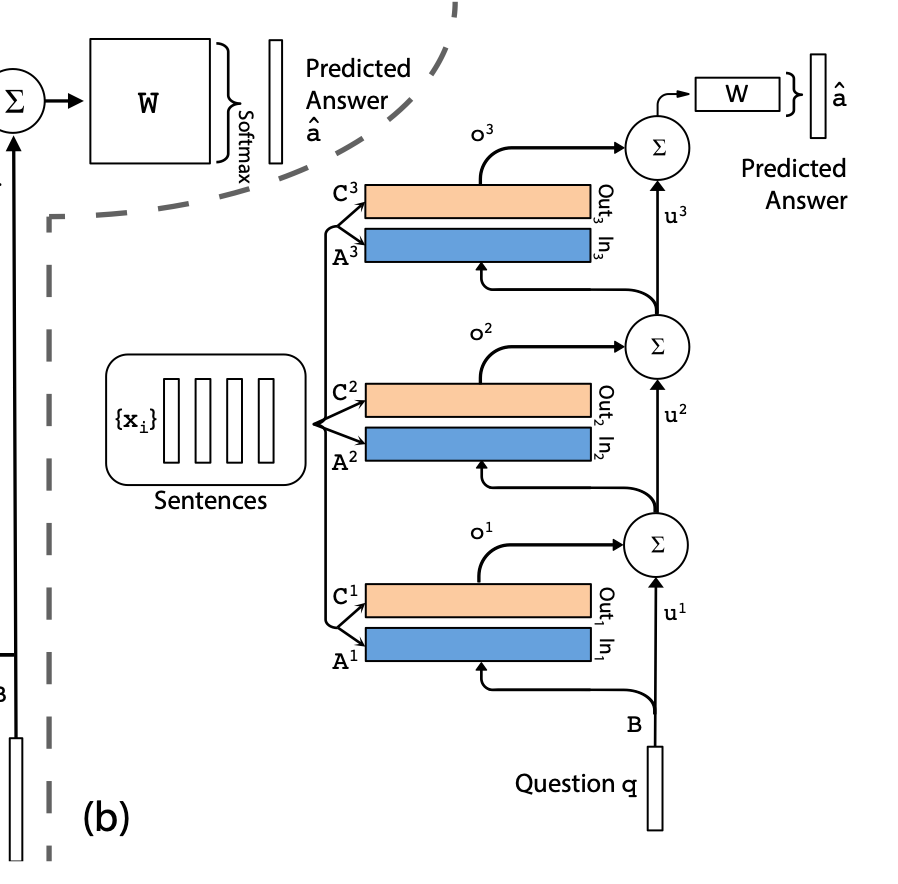
While it's tempting to read this as a clunky precursor to RAG, retrieval augmented generation only focuses on adding information to context before processing by the model.
Weston et al.'s key breakthrough was that memory was something the model itself had access to, not merely something that lived in context. The idea was massively scaled up and applied to transformers in 2021 with RETRO by Borgeaud et al. They made specific engineering choices to make this work at the time:
- A frozen BERT retriever pre-computed an index over memory once.
- At inference time a kNN search retrieved the top neighbors of the current layer's query so the model didn’t have to attend to the entire index. This was a vastly more efficient and sparse approach than Weston's original implementation, and it can be traced to work on approximate nearest neighbor search by Rae et al. on Scaling Memory Augmented Neural Networks with Sparse Reads and Writes in 2016.
- Retrieved chunks were integrated via cross-attention back into the model rather than stuffed into the prompt.
Unfortunately, there were still a few key problems.
Large Memory Layers with Product Keys
The index and the model were built separately so information was only returned on semantic similarity. It did not check if the information was truly beneficial to solving the given query. Moreover, kNN search requires massive external storage and cannot be natively updated via gradient descent.
Fortunately, in 2019, Guillaume Lample et al. started to bridge this gap.
In Large Memory Layers with Product Keys, the authors made sparse KV retrieval a set of parameters, unlike Weston and Borgeaud who treated memory as vectors stored outside of model parameters. Lample's memory layer was a drop-in replacement for a fully connected layer in a transformer block. It consisted of trainable parameters that resemble a set of memory slots, each with their own key and value, that are sparsely queried at inference time and concatenated into the previous layer’s outputs. At the time it was a big deal!

To avoid using kNN so that retrieval was sparse, the magic of the paper lay in a new system altogether:
- Instead of matching a query against all keys to find the top k matches, they create two separate smaller codebooks of half the original size and find the top k matches in each one.
- They then concatenate the keys fetched from this first step, which now resemble the original full key space, and perform a top k retrieval over this set, enabling quick retrieval over millions of entries.
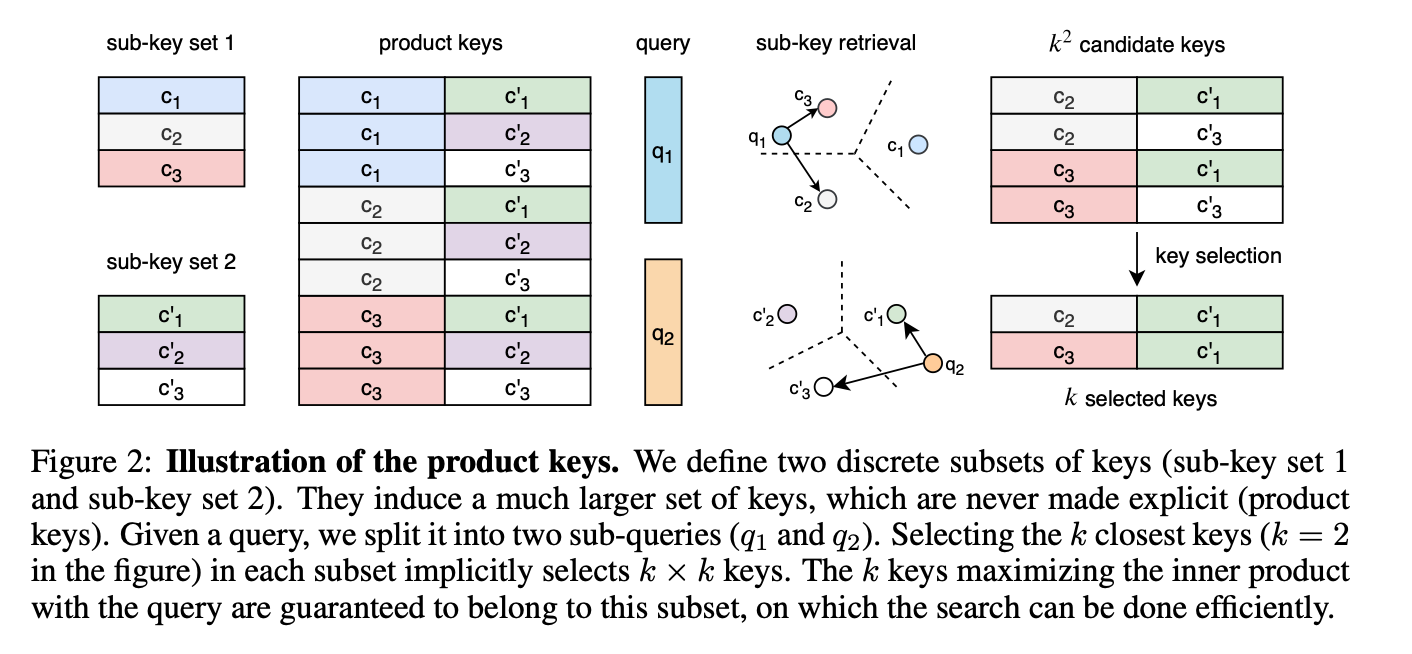
More recently, Berges et al. published Memory Layers in 2024 and scaled up this method to modern large-scale LLMs, demonstrating significant performance improvements.
However, there was still a problem. This memory is trained once and then static, and the only way to update it would be backpropagation. Ideally, we could map new documents to embeddings and subsequently a space of keys and values that the model has learned how to sparsely retrieve over mid-layer. The keys and values don’t have to be static at inference time, but the model will have understood how to retrieve over the space in which they live. By jointly meta-training an embedding and encoder model for key value representations with the main network, marginal new information could also be immediately sparsely accessed by the model.
Going forward, I’m excited to see more work that adapts work from this line of architectures to sparse mid-layer retrieval for modern agents!
Test-Time Training
Let’s update weights all the time
Beyond the problem of retrieving semantic-memory or episodic memory, as agent tasks stretch from weeks to months, more attention has now fallen on how models can continually write information to themselves.
At the token level, most current systems don’t simply write to context, but instead focus on context engineering for handling growing working memory. Agents commit information seen early in a trajectory – from tool-calls to error strings – into file system memory since it could be critical to reasoning a hundred time-steps later (who knows). Today we have started to post-train over model-harnesses so that agents accurately evict storage and retrieve this working information. While this is necessary, we are still bottlenecked in this approach by only being able to store token-level information in file systems, while the model itself remains fixed.
Recent papers have suggested revisiting test-time training to attack this limitation. They want to update model weights over the course of a single agent episode, and in the last year there have been several new papers in this direction.
Learning to Discover at Test Time from Yuksekgonul et al. suggests that when trying to generate a novel solution that beats all existing benchmarks on a creative problem, a model should continuously update its policy against a given reward function by overfitting to actions that maximize reward rather than being encouraged to find diverse, exploratory answers. However, most agent setups do not have a perfect reward function to update against, nor do they want to beat a benchmark result at all costs. We must find another way to distill signal from observations into the model. Interestingly, unsupervised objectives have become common as a starting point:
- In End to End Test-Time Training by Tandon et al., the authors suggest that we should perform weight updates using an unsupervised objective on the network’s final layers when new information is seen.
- In Titans by Behrouz et al., they create a new inner memory model inside the main network, which alone is updated with local gradient descent on an unsupervised objective to remember activations from the previous layer, thus compressing and extracting some useful signal from the activations.
Going forward, there’s no reason why we can’t do weight-based test-time training across multiple episodes for distilling new insights. However there are two key problems with the aforementioned methods.
Catastrophic forgetting and smart objectives
Firstly, unsupervised objectives might be helpful but do not teach a model which information during a trajectory is useful to remember in order to solve a problem. They simply tell it to store everything it has seen.
Secondly, if a model has fixed capacity, simply overwriting weights leads to catastrophic forgetting and previously integrated information being lost. This is explained expertly by Jessy Lin in a recent blogpost. When thinking about making models continually learn, it’s not just about distilling the right bits of information from a given piece of data but integrating them with what we already know without degradation.
Fast-weight Product Key Memory starts to tackle the second of these problems. It appears similar to Titans, since they perform gradient descent with an unsupervised objective on an internal memory layer. But unlike Behrouz et al. they use Lample’s Product Key Memory Layer instead of a linear layer; it is massively extensible and memory slots can be isolated to ensure there is minimal interference for new updates. Unfortunately, they fail to address the problems associated with an unsupervised objective.
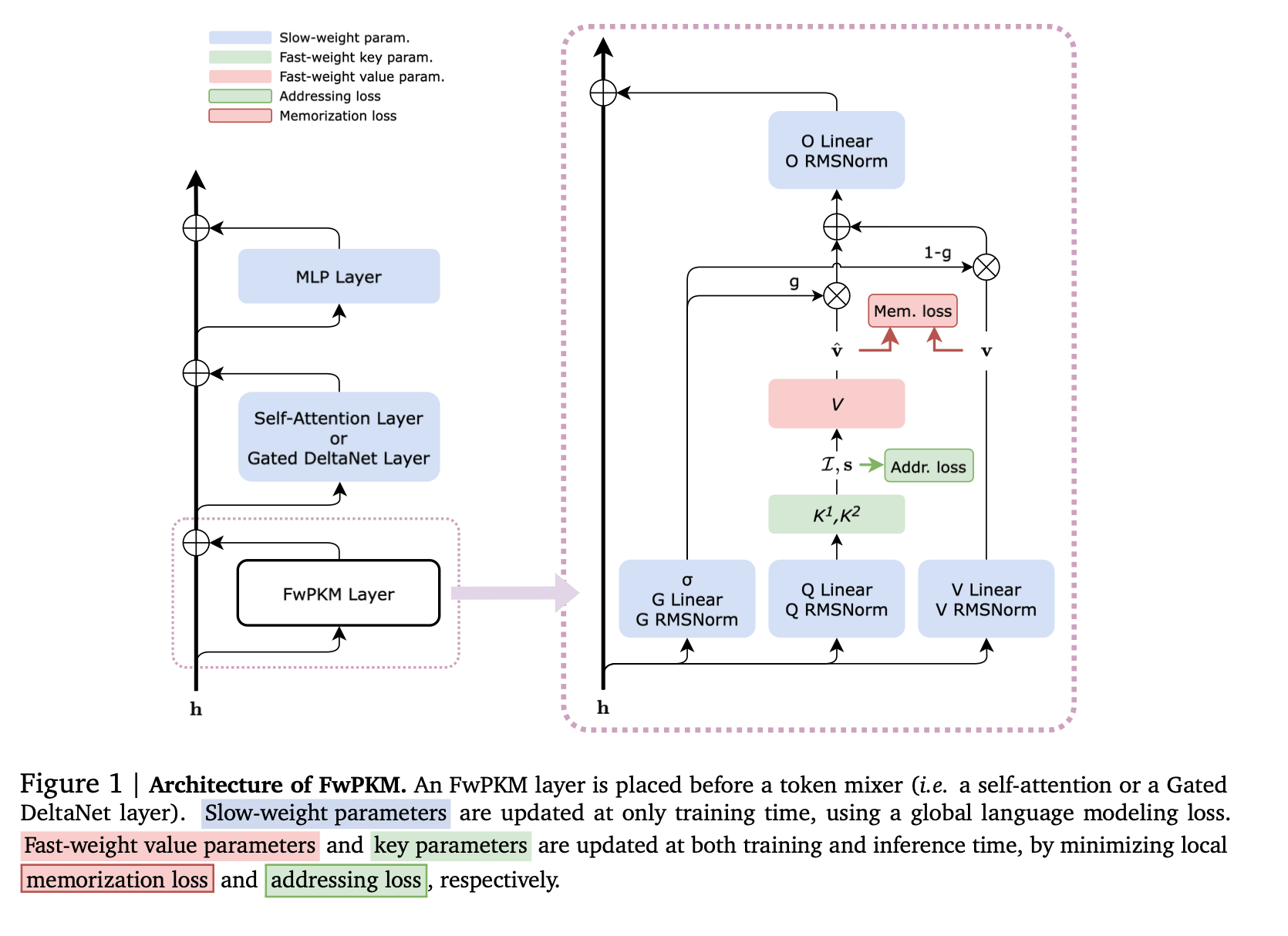
In Continual Learning via Sparse Memory Fine-Tuning by Lin et al., we start to see a glimpse of both problems being addressed. They identify that catastrophic forgetting can be fixed by only updating specific memory slots in Memory Layers by Berges et al. They also use a fine-tuning objective rather than something unsupervised. They even go a step further and use a smart metric to ensure slots that are activated by relatively new information are updated, and slots commonly accessed for common capabilities remain untouched.
As the complexity of test-time training updates grows, a hand-coded metric to decide which parametric slots should be written to and updated will become insufficient. Moreover, deciding what signal to distill from observations back into the model requires significant data curation work online while the agent is operating. Whether we are updating and swapping in and out LORA adapters, or picking the right memory slot in a memory layer, we will need to train a meta-agent that observes live trajectories, creates the right objectives to update the model against and chooses the right substrate for those updates. Analogous to the commentary on Meta-Harnesses earlier, I think this will be a powerful paradigm.
Nonetheless, I think there is still another compelling and complementary axis for storing information online in weights.
The New-er Axis
Today, we think of the decision of how and where to write information to weights as decisions external to the model itself (you may be picking up on a theme in this post).
If we could build a model that itself wrote information to parameters based on information it observed during a single forward pass, we could bypass the meta-learned agent and let the model operate continuously in its environment with its own internal scratchpad. The write policy for weight space would become intrinsic to the model and open a new axis for continual learning.
In particular, I think this could become crucial as we move from reasoning agents to planning agents. In the early innings of language models, we thought of reasoning as something external to models like Chain of Thought rather than native to their latent space like o1. Similarly, I think we will first approach planning agents with external systems that moderate weight updates to internalize observations over long horizons, before we eventually make agents themselves inherently capable planners.
While this is a long bet, and there is no current work today that attacks this line of architectures, there is a rich history of work on this problem.
Neural Turing Machines and Meta-Learned Writes
The memory augmented neural networks we explored earlier enabled us to better read information from external memory. They did not explore how we could also write information to an external memory. Fortunately, this was already an exciting area of research ten years ago.
In 2014, Graves et al. at DeepMind wanted to see if neural networks could act like an actual computer and execute basic algorithms. They wanted to give neural networks an external memory analogous to the infinite tape of a Turing Machine, and make the process of reading and writing content to it differentiable so that the system could be end-to-end trained.
The system consisted of two components: a controller RNN and an external memory matrix. At each time-step of the controller RNN, its hidden state was used to compute a set of hyperparameters that outlined how to read and write from the external memory.
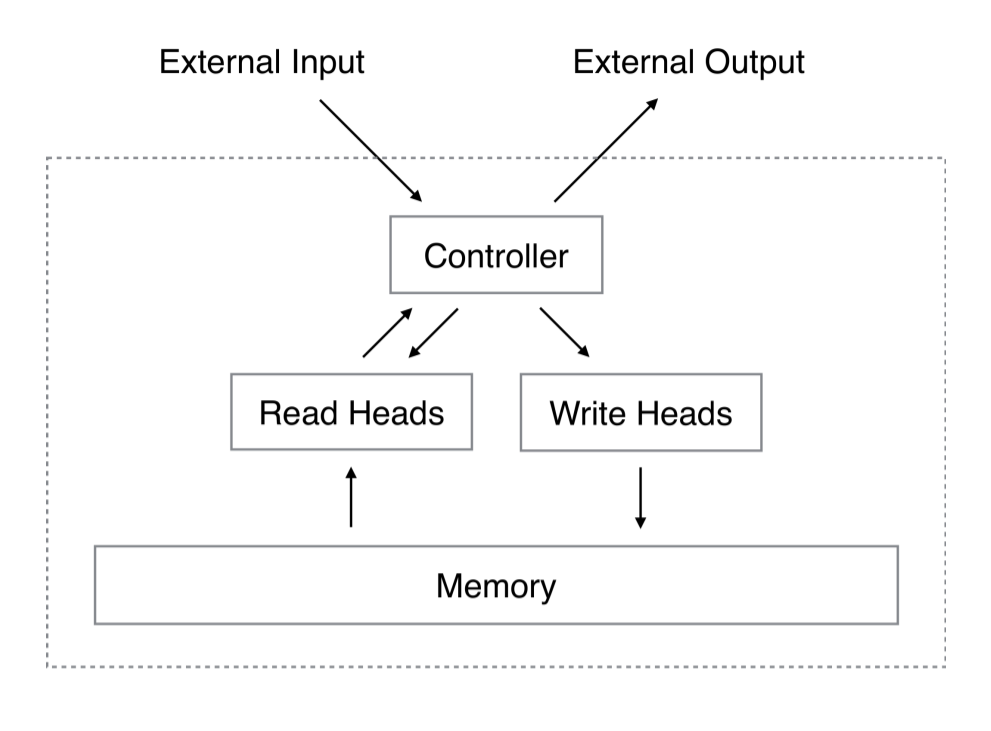
The authors used a combination of content-based and location-based addressing to do the reads and writes. Content-based addressing functioned very similarly to attention, while location-based addressing enabled random access as well as pointer-like behavior within memory to execute basic sorting, copying, and associative recalls. Two years later, Graves et al. actually followed up with Differentiable Neural Computers which improved on NTMs by freeing unused memory and tracking the order of write operations.
The magic of this paper is that whereas earlier work purely focused on memory reads for question answering, if architectures could write to memory, it could be incredibly helpful for long horizon planning. For example, given enough trajectories at train time, we could teach the hyperparameters a write policy so that a fact seen early in a trajectory could be automatically stored, combined with a function of a slew of subsequent information, and the collective retrieved at timestep 100 to inform a later decision.
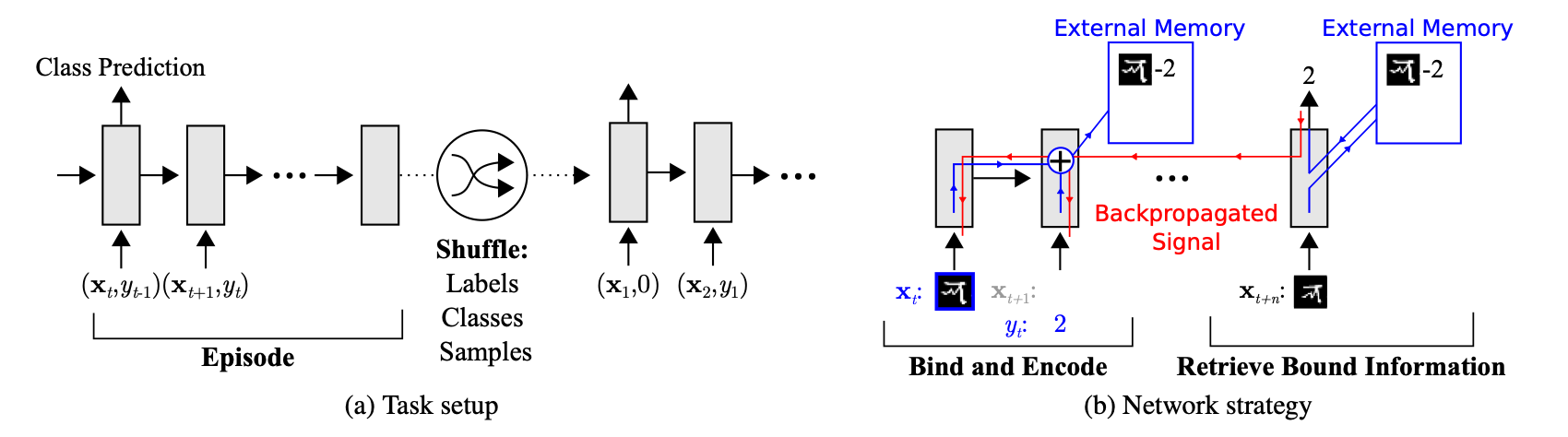
In fact, in 2016, Santoro et al. demonstrated in Meta-Learning with Memory-Augmented Neural Networks that you could effectively teach models how to use these read and write operations in this manner. By meta-training a MANN over many one-shot image classification tasks, they showed the controller could learn a generalizable strategy for binding new observations into memory and retrieving them at the right moment — even on classes it had never seen before. The write policy itself was generalizable across classes and stored network activations appropriately for later use. As we move into a world of long horizon planning problems for computer use, this could become an invaluable dimension for scaling.
Conclusion
If it wasn’t already clear, I should restate that I do not think the world of retrieval or continual learning is binary. I believe that token-level or activation-level work for retrieval, or classic weight updates in parameter space for writing new information is important: both meta-harnesses that envelop Cartridges style approaches, and meta-agents that decide how to update and swap LORA adapters continuously are vital components of future agentic systems. I simply also believe that on a complementary axis, architectures can make models themselves capable of reading and writing information to open new axes for scaling retrieval and test-time training.
Moreover, it goes without saying that for any of this research to materialize, there are significant systems-level bottlenecks. While Mixture of Experts theoretically dates back to 1991, it was only clever infrastructure engineering that made them a reality from 2017 onwards. In Berges et al’s Memory Layers paper alone, the authors had to parallelize embedding lookup and aggregation across multiple GPUs with memory values sharded on the embedding dimension, as well as share parameters across multiple memory layers. If we’re ever to see versions of Memory Networks, RETRO and Neural Turing Machines make a comeback, this is where the real battleground will lie.
In a world that sometimes shies away from architecture research, or at least overly focuses on the perils of quadratic attention, I hope this post’s contribution is that architectures are as alive as ever. I’m excited to see new research re-discover how retrieval, test-time training and many other core primitives of agentic systems can go from being externally controlled artifacts to being intrinsic to the model itself.
If you’re interested in reading more about this space, we put together a reading list of papers from the last few years. You can check it out on GitHub here.