Datology's distributed pipelines for handling PBs of image data
Disclaimer: Datology is an Amplify portfolio company.
In his talk at NeurIPS in 2024, OpenAI co-founder Ilya Sutskever had a now-famous slide titled “Pretraining as we know it will end.” The idea is that while compute (and the efficiency of it) is growing fast, the actual amount of data we have to train AI models on is not growing fast, or even at all.

Through this framing, the internet pre-training corpus is like fossil fuels: there’s a limited amount of it, we’re using it all, and we’re not going to discover more of it any time soon. In this new world without low-hanging pre-training fruit, the only way towards exponentially better models is new architectures, synthetic data, and more inference-time compute. The internet corpus… is what it is.
But what if it wasn’t? This is the idea behind Datology, the most interesting company in AI that you haven’t heard of (yet). Their research (for example, NeurIPS' outstanding paper in 2022) shows that you can achieve state-of-the-art results through better data selection alone – deduplicating, manipulating, and otherwise changing the dataset you already have – without any architectural innovations. We don’t actually have but one internet – there’s a massive amount of alpha left in simply redefining how we look at and use the data we already have. And early results productizing their years of research are showing incredible results at training faster, better, and smaller CLIP models.
Taking years of research and making it a reality in product is no small feat, and to accomplish this the Datology engineering team did some truly herculean work. This read is going to go behind the scenes of how they built distributed pipelines that support their researchers working with PBs of web data. Based on extensive interviews with their team, we’ll go into technical detail on:
- Why working with images is distributed by default, and how that makes it hard to support researchers
- Datology’s architecture: reusable operators for PB-scale image manipulation operations like filtering and deduplication
- Their custom orchestrator built on Flyte and their own data catalog
- Deploying K8s clusters directly into heterogenous customer environments (and it works!)
Let’s get into it.
The AI company that's actually a distributed systems company
To get into why Datology’s engineering team has had their hands full, let us take a brief detour to understand what makes data curation difficult in the first place. The concept is pretty simple: do a bunch of operations on a dataset to isolate and/or modify only the data points that really make a difference in training a model. Operations include things like deduplication, embedding, clustering, filtering, etc. Any data engineer readers have undoubtedly done some this before when building a pipeline. What is the big deal here, exactly?
Big, huge, massive datasets
Big deal is actually exactly the right phrase, because dataset size is the first thing that makes what Datology does interesting. Everything for Datology is big. How big is big, you ask? Josh Wills, who you may know as JosH100 on his critically acclaimed X account1, works on these pipelines at Datology. Before this, he wrote Slack’s search indexing pipeline – the thing that indexed literally all of Slack – and he works on stuff that’s bigger than that here. At the time Slack was around 2,000 people; Datology is 30.
To get more concrete, Datology’s recent pipeline (which beat SOTA CLIP in speed, cost, and efficiency) was built on the DataComp XL dataset. This thing contains 12.8 billion (yes, with a B) text-image pairs, which rolls up into a cool 600TB. Needless to say, one does not simply download this dataset; anything you do with it immediately becomes a distributed systems problem. In total, including historical datasets kept for reuse, Datology has around 5-6 PB of data right now.
The reason things need to be this large is that when you’re doing curation, your goal is to take a pool of a ton of data, sift through it, and find the stuff that’s actually useful to you. And the only way to make sure that these techniques work on these massive datasets that Datology will encounter at a real customer is to test on massive datasets internally. Essentially, almost all of the research that they do internally necessarily has to be done in at least semi-productionized settings.

Composability and research enablement
The second thing that makes the job of Datology’s engineering team not so simple is the fact that they are in the business of research enablement – giving their research team the ability to construct pipelines of arbitrary complexity. It’s not enough to build a distributed pipeline that can deduplicate 10B text-image pairs; research also needs to be able to run this as part of a multi step pipeline with other operations, in any order, any number of times. You can think of engineering’s primary job as building Lego blocks for research…but like, really complicated Legos…or something.
But their job isn’t only research support, because Datology has customers, and these pipelines need to eventually get deployed inside those customers’ environments and actually work. Their engineering team has built a near-foolproof and highly complex build pipeline for their…pipelines…to deliver them to customers and run in a distributed environment, which I’ll cover later on.
I’d also be remiss if I didn’t mention the hardware component here. Researchers coming from academia – and certainly large AI labs too – are used to a particular level of luxury. I’m talking, of course, about unfettered (well, at least not very fettered) access to H100s. Every training run and every transformation is done on state of the art hardware.
But in the real world, H100s and H200s are harder to come by. Designing workloads with the assumption they have access to these GPUs means they won’t translate well into real, reproducible pipelines on customer environments, many of whom will decisively not be operating on the hottest new NVIDIA bling. Part of the challenge for Datology’s engineering team is making this equation work: taking off the shelf frameworks (Spark, Ray, etc.) and making them work fast and clean for both types of environments: on SOTA hardware, and run of the mill hardware (sometimes, without GPUs at all). And doing so economically.
Anatomy of an operation: exact deduplication
With all of the operations – the individual manipulations that go into a data curation pipeline – that Datology’s engineering team have built, there’s more than meets the eye. A great example is how they built the ability for researchers to deduplicate datasets.
One of the most intuitive ways to curate a dataset is to remove duplicates. On the kinds of pre-training that we do for models today, the datasets are chock full of overlapping and duplicate data; removing it would allow us to train faster, cheaper, and get the same results.
With images in particular, there’s another important reason we need to deduplicate. Can you guess what the most common image found on the internet is? Ironically it’s actually “Image Not Found.” In the 11B images in the DataComp dataset you have a ton of these, and there are more of them than there are anything else individually. Obviously, they need to go.
But how?
The naive way (it does not work)
The naive thing would be to compare every image to every other image. But this doesn’t work for straightforward performance reasons.
Comparing all to all would be O(N2), which is not an option with 11B text-image pairs. 1.21e20 is already wild to think about: it’s more than 10 times the estimated number of grains of sand on earth.
Not only that, but behind the scenes Spark would need to make sure that individual nodes are communicating with each other about what their contents are, any sort of process for broadcasts, etc. If you had one huge box it would be O(N2), but in a distributed setting it’s even less performant. And even then, if you spun up tons of machines, you still wouldn’t be able to load all of the data into those machines at the same time; you’re only able to access a subset of data at a time even with your cluster of boxes.
The clever way (or “this also turns out to not be trivial”)
To get around these problems, the solution looks something like this. You start by computing a hash for each text-image pair, which compresses them down to a more manageable format. You then aggregate images with similar hashes together on the same machine. This is a standard pattern in Spark called a Shuffle Join or Shuffle Hash Join.
With all of the similar hashes of a particular type on a single machine – such that we can say they are duplicates – you need a mechanism for deciding which one of these duplicates you want to keep in the dataset. This also turns out to not be trivial when dealing with text-image pairs, because the same image (duplicates) might have very different captions, and some captions will be better and more descriptive than others. You need some sort of score2 to decide which is best, and keep that particular one.
Once you’ve decided which of the text-image pairs you want to keep in the dataset, you then need to implement this decision and filter the dataset. You can do this by reprocessing the entire dataset and iterating through every single image, deleting or removing every image whose hash doesn’t match the particular document ID that you decided to keep in the previous step. This also turns out to not be trivial. Because even though the hashes are much smaller than the entire dataset, they’re still pretty huge; so you need to do another pass through the data to figure out which images with which hashes are in which files.
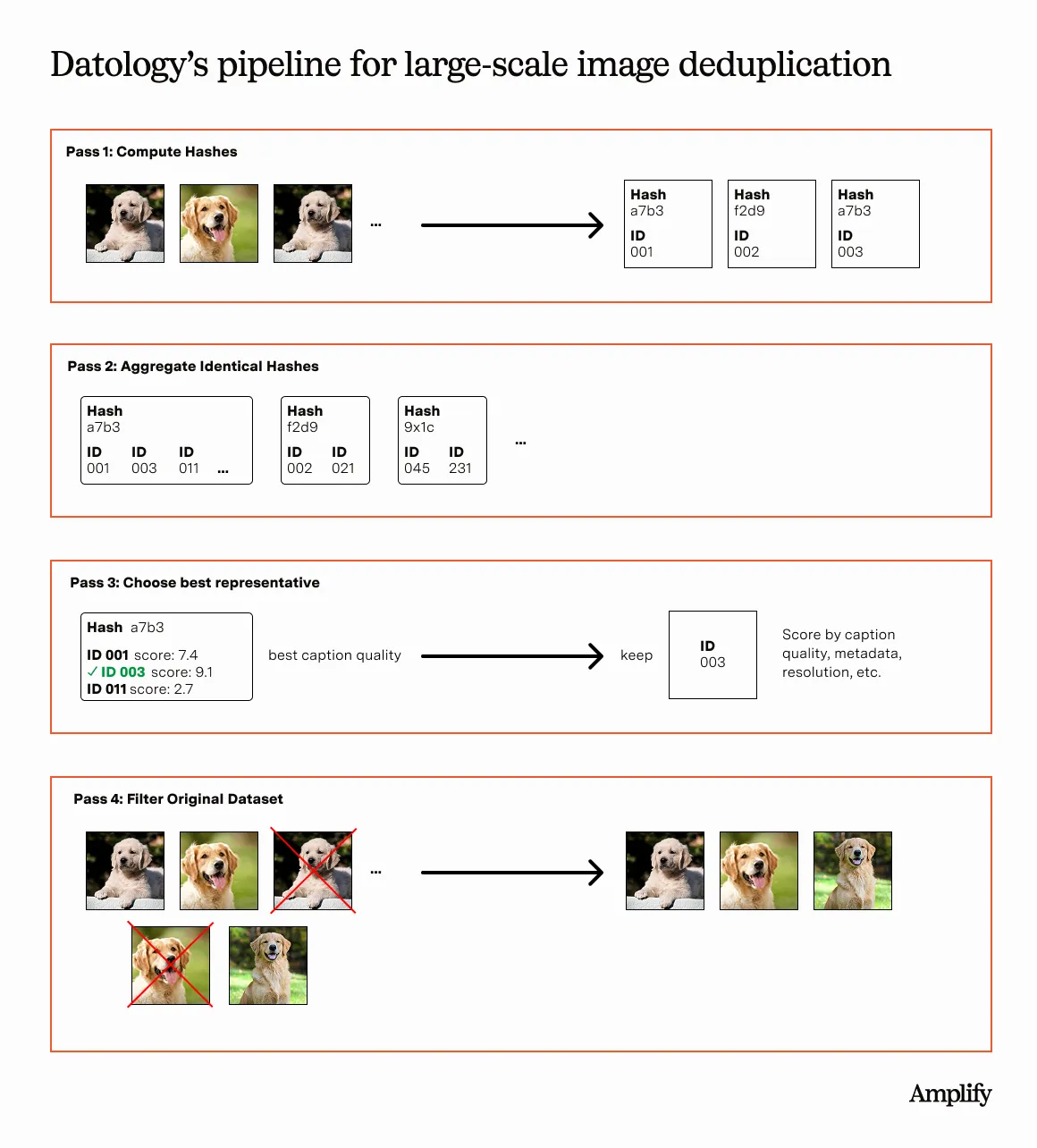
This “clever way” is part of how Datology really does deduplication today that doesn’t require an O(N2) join and can scale out to thousands of machines and billions of images. It took a lot of tuning and cleverness to do what seems like a simple operation. And much of it rests upon a particularly difficult join pattern.
The two step…shuffle…bucket…join?
There’s a join pattern that’s popular across all of data curation that doesn’t really exist in vanilla Spark. It’s where you want to join between two datasets where one is vastly larger (like 1000x larger) than the other. The smaller dataset still isn’t small enough to fit in RAM. The most common use case for this is deleting duplicates from a larger dataset that are in the smaller dataset, but it’s more common than just that.
The canonical way of solving this in Spark is via the Shuffle Join / Shuffle Hash Join. Here you would ship all of the data from both of these datasets over the network, in such a way that the right data from each of the datasets ends up on the right executors. But this doesn’t work for the size of data that Datology is working with – it inevitably runs into network failures, and the whole job fails.
Josh had to deal with this problem at Slack to make indexing work, and had to deal with it again here to make curation work. The solution is not a broadcast join (this exists in Spark). It’s not a hash join. It’s also not a shuffle merge join. He is still working on a name for it (one of the hard problems in computer science). But here’s how it works.
Step 1: creating an index of matching files.
This works because instead of shuffling the entire dataset, we are only using a small subset of information: document IDs and file names (not entire images).
- You start on a single partition of the large dataset and a single partition of the small dataset.
- You grab the document ID and the file name from the larger dataset, and just the document ID from the smaller dataset.
- Join these via a regular Spark join (it will hash the document IDs).
- You run this for every partition on both datasets.
This intermediate output tells you which files in which partitions in the large dataset need to get operated on (removed, in our case). Then in step 2…
Step 2: using the index to filter the large dataset.
- You do a single, very parallel pass over the large dataset.
- You use the file name as a key, and join it to the intermediate output from step 1 to know which files to keep and which to remove (or do some other operation on).
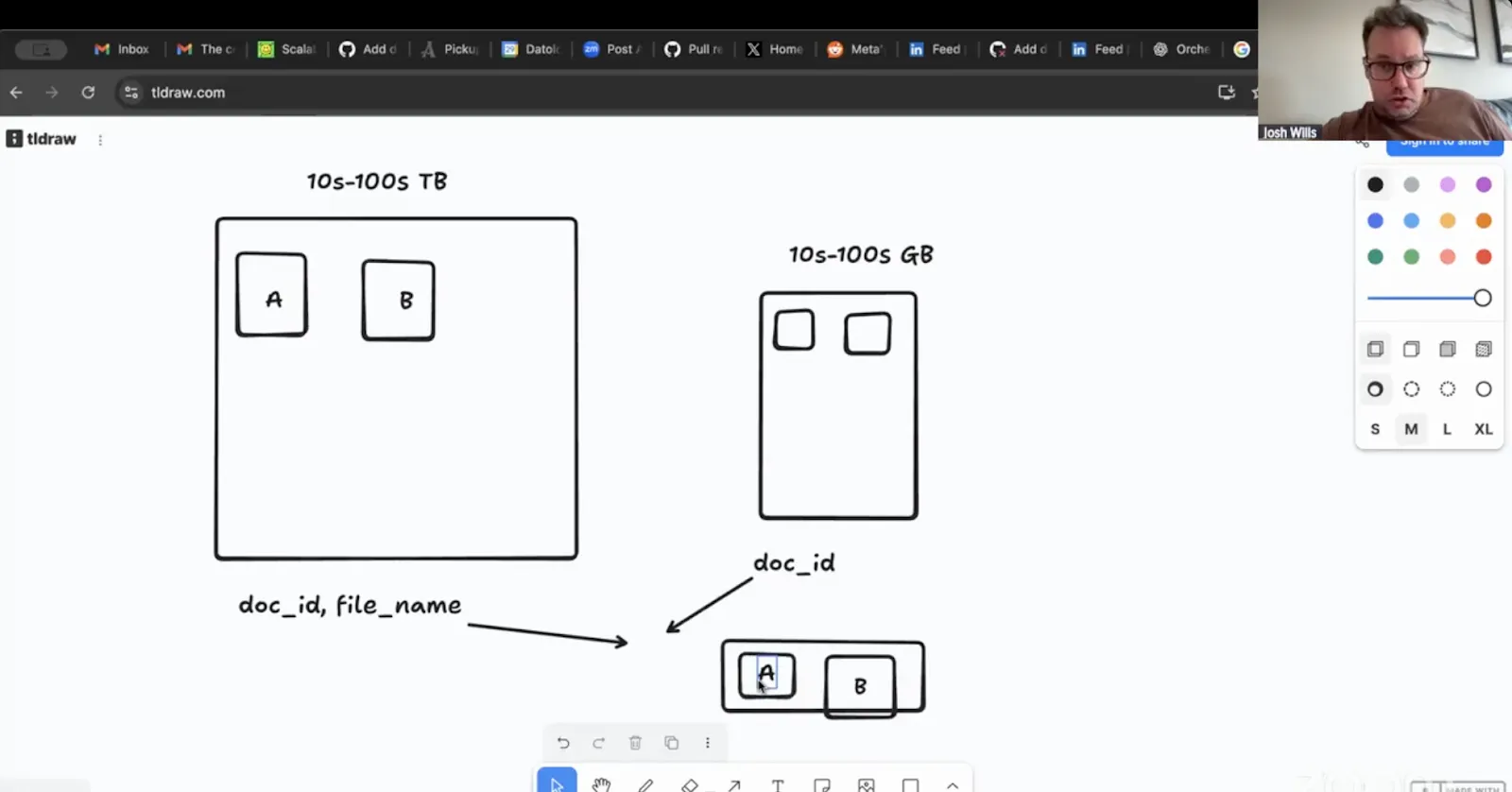
Josh still doesn’t have a good name for this – but perhaps you do. Let us know.
Other operations
Across the board at Datology there are 5-6 core operations, and each of them is composed of between 1 and 4 big manipulations that need to be done for them to function. These all run up against their own set of constraints:
- A lot of these manipulations are network bound, so the team spends time waiting for the network to do its thing (with these massive datasets, not much you can do here).
- Other stuff, like clustering, ends up being memory bound. To maximize the amount of data you can put in RAM, you need compact representations, which means you need the right file format.
- They still do a lot of stuff on GPUs…just not the most expensive, huge GPUs.
Datology operations are essentially exercises in gotchas. Everything that seems simple on the surface is…not.
One example: when it comes to text, researchers often want to be able to write out a specific amount of tokens. But all of the normal operations that you’d do on Dataframes in Spark aren’t based on the number of tokens; it’s based on the count of rows. Just giving researchers the ability to filter to a specific token count isn’t as easy as doing a cumulative sum, because you’d be aggregating over these absolutely massive Dataframes.
Another one is shuffling. Typically when you ingest a dataset, shard it, and put it through a pipeline, you don’t really care what the order is. But when you actually end up using that data to train a model, it becomes very important that the data isn’t in some sort of degenerative ordering. Let’s say as part of your curation pipeline, you cluster some data and then write out individual clusters to individual partitions. If you were to then train a model when your data is ordered by cluster, things would get bad quickly. So shuffling before a writeout is a must.
Infrastructure and orchestration
Now comes the fun part, the tools that Datology actually uses to do the job. First, file formats.
Datology uses Parquet. Which might be surprising to you if you’re coming from the training world. When you’re doing model training, everything is row oriented as opposed to column oriented. You want the training set to already be together, you don’t want to have to assemble it on the fly (via taking full columns from different partitions).
That is why for training image models, there’s a format called WebDataset. It is essentially fancy Tar files, and most of the open training formats are designed around it. Many of them originate in an academic context, where the constraints around what file format you’d want to use are looser and less tied to production; a professional software engineer would probably not choose WebDataset a priori.
Datology still uses Parquet3. Because curation does not happen on a row oriented basis, because they are using a lot of Spark (which plays nicely with Parquet), and because it’s incredibly stable by now.
Orchestrating these pipelines somehow
There is no shortage of workflow orchestrators out there. Datology tried most of the popular ones (and spent a lot of time in particular with Dagster) but found them all wanting for building these massive, distributed, modular curation pipelines.
Most of these orchestrators were designed to run the business dashboard every day (or every hour, etc.). Datology never does that – they run a de novo pipeline every single time. They also have some other…unusual requirements:
- The orchestrator needs to know about every pipeline that has ever run, even if only once, so they can reuse the bits of it that are already solved and don’t need to recompute things from scratch.
- It needs to be able to run all sorts of jobs: Ray stuff, Spark stuff, GPU stuff, and they all need to play well together.
- You need full traceability for every pipeline artifact going back in the annals of history: what were the inputs, what specific commit did a researcher launch this thing with, etc.
The solution they settled on is actually two things:
- A heavily customized version of Flyte modified to bypass long task startup times.
- A custom data catalog in Postgres that granularly tracks every single pipeline.
The Flyte part is pretty simple. Flyte 1.04 runs on K8s and thus startup takes quite a long time for any individual task – typically upwards of 2 minutes. Datology’s pipelines can have dozens or more steps; if a pipeline breaks at step 45, the whole thing needs to run again and each step gets that 2 minute penalty. So they forked Flyte and rewrote the parts of the source code that deal with how jobs get split up into Python workers. And that messed up the UI (which shows progress on a task basis), so they needed to customize that as well.
The data catalog is probably the more interesting part. Most workflow engines have short histories – there’s really no reason you’d need to know the exact parameters of a job that ran 6 months ago. Datology does need that information, such that when a researcher comes along after a job, they can simply reuse the data from it if it matches what they want to do today. Their data catalog is built in Postgres and tracks every single job, all of the parameters it took to construct it, where the data is located, and the version of the code that was used.
Deploying this thing into a customer’s environment
So Datology’s research team is assembling all of these impeccably built, distributed operations and combining them (hopefully) into a data curation pipeline that works for a customer’s needs. Then comes the fun part; getting this pipeline deployed in a customer’s environment. Remember that each pipeline is different, depending on what a customer’s goals are (e.g. training a legal mind, a coding agent, etc.).
The answer is a very customized Kubernetes cluster that needs to be able to:
- Handle heterogeneous job and queue types. Datology pipelines will be running Spark, Ray, and native K8s jobs.
- Spawn workers with very different hardware. Some jobs will need a lot of RAM, some will need GPUs, and others can run on plain CPU. A big clustering job in Spark typically needs a lot of RAM, while an embedding job will need a GPU.
The customer deploy and the internal deploy for Datology are identical. As they work to deploy to a customer, they would then redeploy internally, and vice versa. For AWS-based stacks, this gets done via CloudFormation and then some subsequently spun up nodes that run Helm installs. There are also some pieces during the Helm installs that need to reinvoke CloudFormation scripts.
Several of Datology’s customers want them to deploy in a totally airgapped setting with no network access, which adds a wrench into some things. As part of the airgapped setup, Datology has mirrors of every single one of their dependencies such that they can be bundled together into this single delivery.
Here’s another airgapped fun fact: IAM roles are only available in Amazon’s east data centers. So if you’re not on east 1, and you’re deploying in a setting where you don’t have network access, you can’t make a change to an IAM role – you’d need to deploy a smaller CloudFormation stack that does have access, make the change, and then resume what you were doing. It is never as straightforward as it seems!
It’s not even just installing it that’s hard, removing it is too. The script to uninstall Datology from a customer’s environment is something like 2,000 lines to shut down resources and clean it up.
“I suffer from the engineering disease where I don’t think that anything I can do is that interesting.” – Josh
Datology’s engineering team has done some of the most interesting work that I’ve profiled over the past few years. They’ve built a general purpose pipeline building system that operates at distributed scale, on economical “non-elite” hardware. They’ve pushed Spark (and lots of other things) to the limits and lived to tell the tales. And then they figured out how to get all of that running in a real customer’s environment. Most importantly, this stuff works: models built on Datology curated data are significantly faster, smaller, and more efficient.
The good news is that they’re hiring. And if data curation sounds like something your company might need, you can get in touch here.
1Probably by someone.
2This score might be calculated by a model, which introduces a whole other can of inference performance worms.
3They have explored Vortex recently, though.
42.0 is rewritten in Rust and should likely avoid this issue, but is still only in research preview.