
The infrastructure behind Runway Characters
Most of you probably know about the Turing Test. Originally called The Imitation Game in his 1950 paper, it was Alan Turing’s proposed idea to test a machine’s ability to think:
I PROPOSE to consider the question, ‘Can machines think?’
This should begin with definitions of the meaning of the terms ‘machine’ and ‘think’...
…The new form of the problem can be described in terms of a game which we call the ‘imitation game’.
Since then, much podcaster milk has been spilled on whether LLMs meet this definition. And though you can quibble on the specifics, LLMs mostly pass the Turing Test in a technical sense; their textual output is indistinguishable from that of a human when graded by humans.
Multimodally, on the other hand, GenAI models have a long way to go before they fool the judges. Though voice models are getting better and faster every month and Nano Banana 2 can fool even the most technologically-savvy of boomers, we are still clearly in the early days of models generating anything other than text. But that’s starting to change.
A few months ago, Runway released their first general world model (GWM-1), and on top of it an impressively lifelike avatar experience called Characters. It’s the first real-time video model the world has seen, generating frame by frame at 24fps with <160ms latency.

Before GWM-1, Runway models were all offline, meaning they operated in a pseudo request-response mode. The most recent offline Runway model is Aleph 2.0, which allows users to expertly edit videos with just prompts and keyframes. Diffusion pipelines take time, especially for longer scenes of video, and 30-60 second (or longer) wait times are commonplace and accepted by users…a far cry from real-time.
So how did they do it? How do you take an offline model like Aleph 2.0 and turn it into something that works in near real-time?
This is the story of how Runway’s research and engineering teams built the world’s first autoregressive video model for Characters, featuring:
- The anatomy of what happens technically when you talk to a Character
- The emerging discipline of research and product, and how the two inform each other
- The training of GWM-1: turning a non-causal model into a casual one
- Hardware parallelization of diffusion and decoding
- Inference optimizations like CUDA graphs
Click on any section above to jump through.
What’s actually happening when you talk to a Character? Once a synchronous session is created between Character and user via WebRTC, the flow looks like this:
- You speak into a microphone to the Character.
- An audio agent processes your voice and passes it to the model.
- The model generates video and audio via diffusion in latent space.
- A second VAE model decodes that video and audio into pixel space.
- The video and audio are sent back to you and rendered.
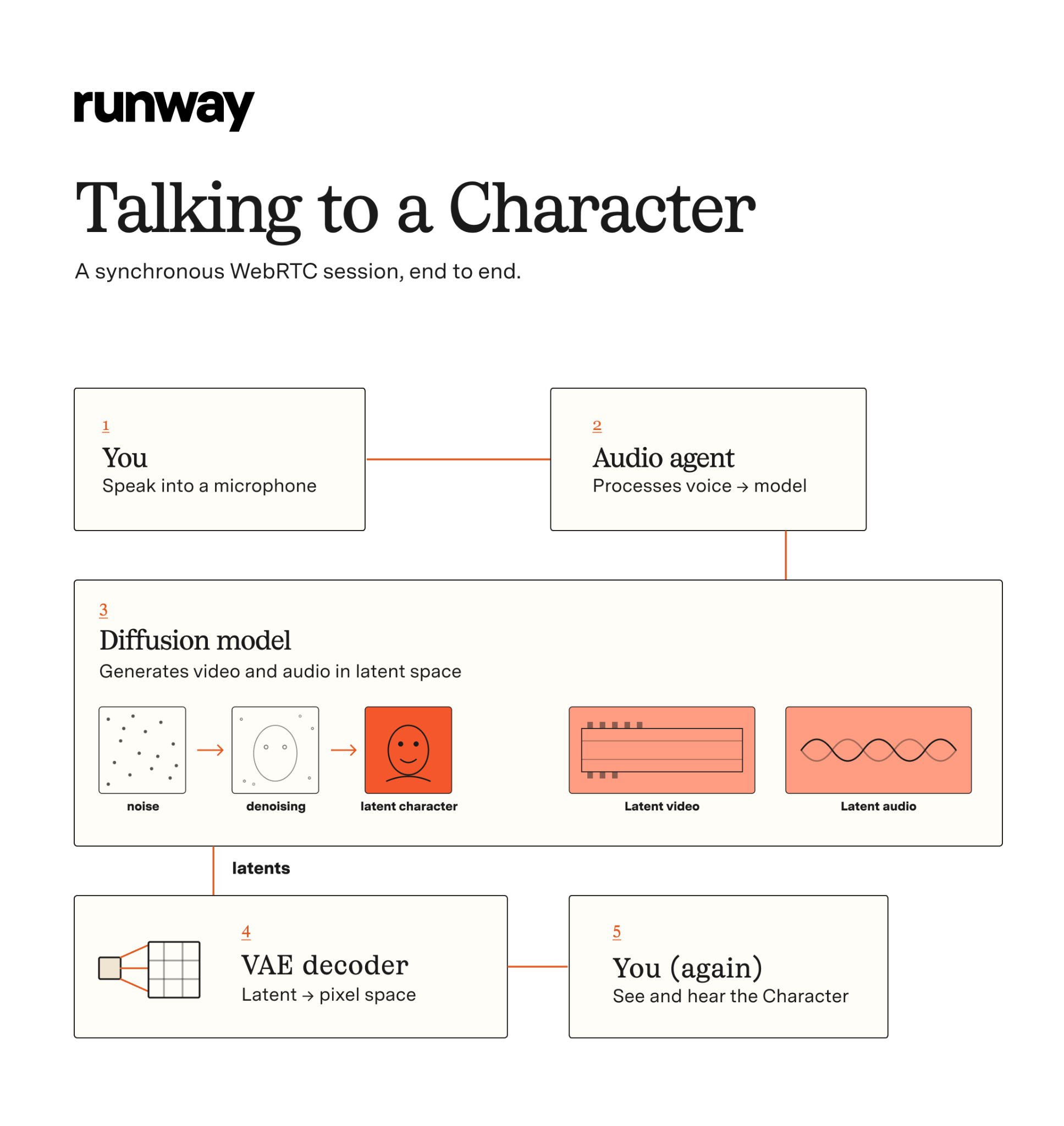
All of this happens in real time, at 24fps, with <1.75s of end-to-end turnaround latency from the server. The model can generate continuously for more than 40 minutes without meaningful quality degradation; character faces remain stable without morphing issues, and this all works across a variety of animated styles including objects and masks.
Characters are also customizable. You can generate a full working Character with a single image of a person or object (I tried making one of myself, which I do not recommend). You can customize and ground responses via adding documents to the Character’s context, as well as set up a framework for tool calling. The idea is for businesses to build their own Characters into internal or user-facing product experiences (e.g. a live customer support character).
Maybe most importantly, the characters actually look pretty good. Simulating human expressions and movements has proven surprisingly difficult – thanks to millions of years of evolution, we are uniquely attuned to the minutiae of what a flicker of the eye, a slight scowl, or a wry smile might imply. Previous generations of AI avatars have largely flopped not because they look wrong, but because they move wrong.
All in all, what seems like a simple product on the surface is, under the hood, an incredibly complex and cutting edge pipeline of a new model and several inference optimizations.
The most important place to start with the Characters story is the model, because it’s why this product exists in the first place. To understand this, we must take a detour for story time.
In what now seems like an ancient past, product and engineering worked together in harmony (🤞) to build experiences. User requirements, customer requests, and a sprinkling of vision would come together into an idea for something, and these two teams would work together to bring it to life. How to balance requirements with engineering time, maintainability, and what else is on the backlog was (and still is) a timeless and delicate art.
With GenAI there’s a third member of this relationship, research. How research, engineering, and product work together to create products like Runway is a messy and emerging discipline, and no two companies approach it the same. Product is now a triangle of sorts, and each piece of it is constantly shifting (e.g. what is a PM vs. an engineer today?).
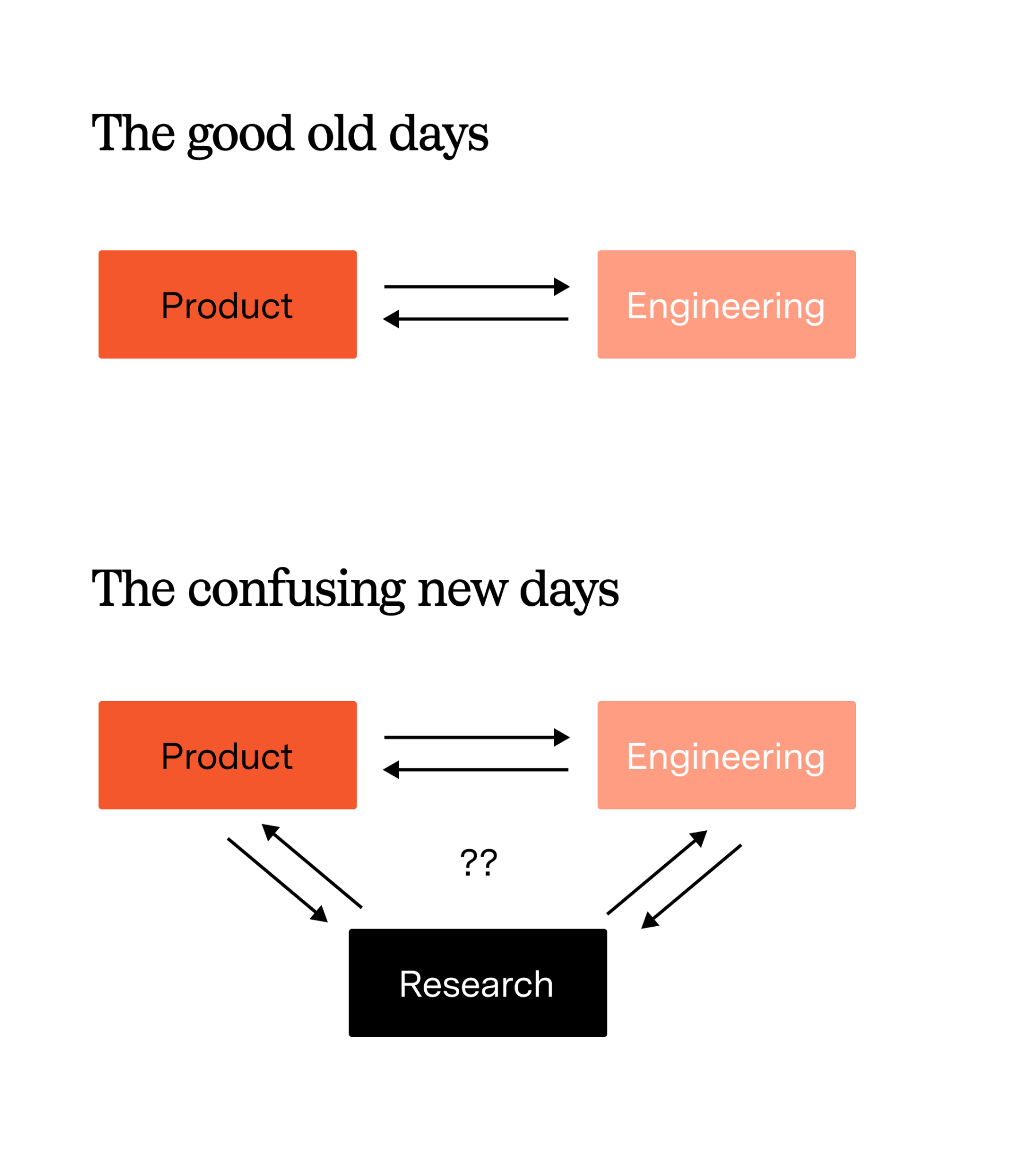
One thing that makes Runway – and this Characters product – unique is how they approach this triangle. Characters was not a product that the company decided they needed to build and then had research “figure out” how to do it. Instead, it was created because of a research breakthrough in training GWM-1, Runway’s first family of general world models.
General World Models are a new category of AI models that, very broadly, build an internal representation of an “environment” and use it to simulate future events within that environment. Runway’s belief is that teaching models to generate pixels and video is the best path towards general purpose world models; at sufficient scale, they’ll have a decent understanding of who the world “actually” works.
GWM-1 is their first attempt. Unlike previous Runway models like Gen 4.5, it’s autoregressive: it predicts frame by frame instead of generating the entire video at once.
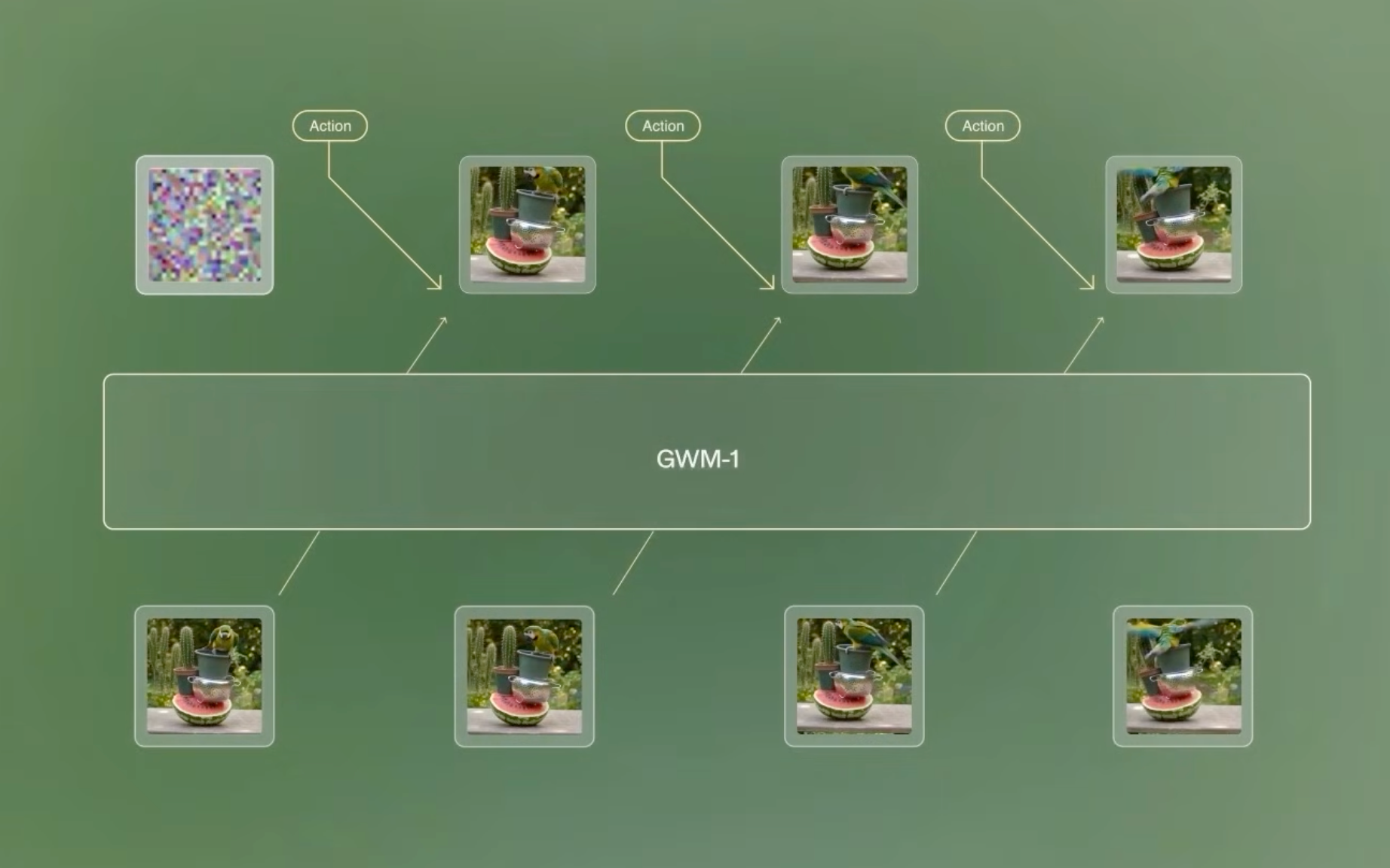
You can intervene at any point in the generation to do things like controlling a robot arm or moving around in space. The model takes that as input and simulates what happens next as a consequence of those inputs. Ergo, the world model.
Runway Characters is one output mode of GWM-1, but there are two others at the time of writing (for robotics and world simulation). You can learn a lot more about the thinking behind the model – plus Yining’s elite sweater game – in Runway’s keynote about it here.

Turning an non-causal model (Gen 4.5) into a causal one
I mentioned that GWM-1 is autoregressive, in some senses like an LLM. And this is how it ends up working in near real-time, by continuously generating shorter chunks of video that are fast, but still grounded in context of the previous frames. This is a major departure from how previous generations of Runway models (and most video models) work, which generate all frames of your desired video at once using bidirectional diffusion.
Frame-by-frame prediction is actually a much harder engineering and research problem than generating all frames at once. One challenge to making this work is that offline video models are non-causal – meaning during training, the model has context of both the sequence before the current frame and after the current frame. This architecture works because the final model is going to generate the entire length of video at once.
But you can’t train autoregressive models like this. They need to be causal, meaning that during training the model only has access to prior context. It’s a lot easier to generate a frame of video when you know what the previous and next frames look like; much harder when you only have the former.
There’s surely a lot more behind the scenes here, but much of the secret sauce behind GWM-1 remains locked in the minds and pens of the Runway research team. You’ll just have to use the models!
As any kernel writers reading this know, any sufficiently fast model in production is the product of a carefully tuned inference pipeline. In Runway’s case making Characters work presented more problems than just fast inference.
A buffering system to sync audio and video
Video models like GWM-1 present the challenge of generating both audio and video at the same time. The audio and video must be perfectly synced when presented to the user, despite the fact that their generation processes vary wildly. Remember, the human brain has a wonderfully precise eye for dialogue; even the slightest lag or mismatch between what the lips are doing and what the audio is saying is perceptible.
To address this, Runway buffers the audio and video so that they can be sent to the user in complete temporal agreement.
On the flip side, audio and video must sometimes diverge. When you’re talking to a Character, they’re nodding their head and listening; there is no audio. And if you interrupt them while they’re talking (as is your right), Runway needs to instantaneously pause audio generation faster than the next video frames can be generated. In this scenario, they also need to clear the queue/cache of buffered audio (“flushing the buffer”) since the user is conceivably interrupting to form a new line of questioning.
Modern diffusion techniques operate in latent space, a compressed version of pixel space. Accordingly, inference for these models requires two steps: (1) generating the latent representation via diffusion, then (2) decoding it into human-readable pixel space. Decoding is faster than diffusion, but still not fast enough to do sequentially if we want to generate video in near real-time.
Runway parallelizes these steps, offsetting by 1 frame. They also run the diffusion model on separate hardware than the VAE. The former is sharded across 4 GPUs, while the latter has its own dedicated hardware.
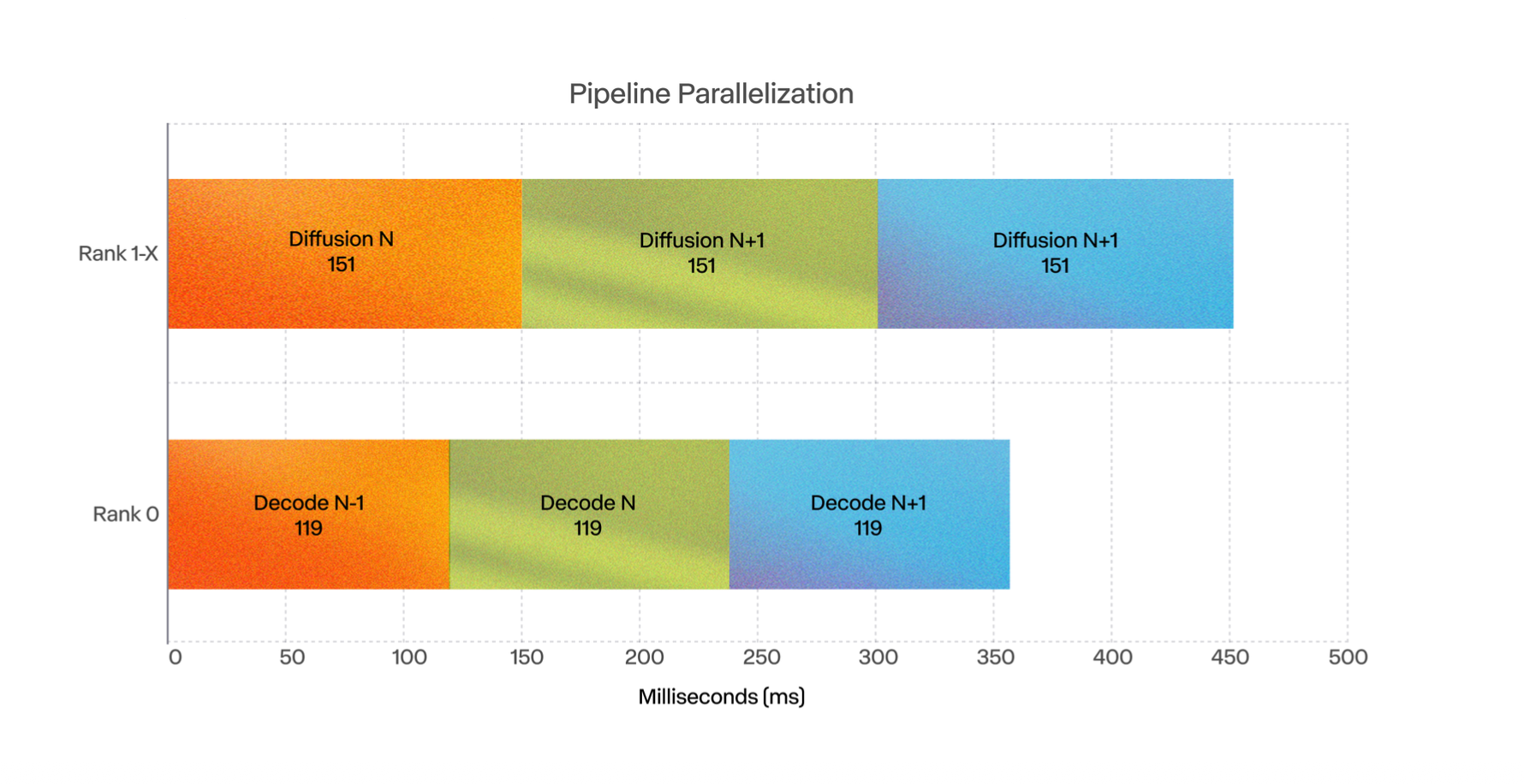
Via this method, latency is something more like max(diffusion time, decode time) instead of (diffusion time + decode time).
CUDA Graphs and the KV cache
Early on, Runway’s research team figured out that CUDA kernel launch overhead was a significant performance limiter. The standard solution is to trace the model as a CUDA Graph, which allows the CUDA Runtime to replay a fixed sequence of kernels with minimal overhead in between. This imposes some additional restrictions on model logic — namely, all tensors involved in model forward pass must remain at a fixed memory location and not change shape over the lifetime of the inference server.
A good example of where this becomes challenging is KV cache maintenance. The easiest implementation of the KV cache Runway uses is a dynamic stack of tensors, where concatenation is used for insertion. That's fine for non-performance-critical scenarios, but in a production use case, concatenating to an existing tensor invalidates any CUDA graph that included the original tensor. So they had to find a different approach where the KV cache never changes memory address or size.
They landed on an implementation where they allocate the KV cache to its maximum size at inference server startup and initially fill it with padding tokens. Inserting new frames is then implemented as a write to a region of an existing tensor, rather than a concatenation (which usually triggers a re-allocation).
While this thankfully makes CUDA graphs feasible, it introduces new complications. For example, computing attention over padding tokens would skew softmax scores for real tokens, so they mask out the not-yet-filled region (block sparse attention can achieve this efficiently too).
Try out Characters yourself
You can try a live demo of Characters here, or get a better sense by watching a Character read this blog post to you up top.
And if this kind of stuff is interesting to you, Runway is hiring.



