
A Deterministic Simulation Testing (DST) primer
Disclosure: Amplify Partners is an investor in Antithesis.
Since the dawn of Middle Earth, it has been somewhat widely accepted that it takes 8-10 years to build a real database. There’s a lot that has to go right; databases need to be rock solid. They need to be battle tested, consistent, fault tolerant, and most of all, trustworthy. These are things that take time to dial in.
But in 2009 a small team of childhood friends in Virginia somehow broke the rule. In a few short years the Daves (Rosenthal and Scherer) and Nick built something that everyone said they couldn’t: a distributed storage engine with ACID guarantees. It was called FoundationDB, it took the world by storm, and then it got acquired in 2015 by Apple (you can still download and use it here).

All in all, from their first LOC to a production ready version with capabilities that no other DB on earth had at the time, this very real database took only a few years to build. How did they do it?
It wasn’t because they had a massive, well resourced team (they didn’t). It wasn’t because they owned any preexisting intellectual property (they didn’t). And it certainly wasn’t because databases had gotten easier to build (they hadn’t). No, if you ask the FoundationDB team why they were able to pull off what they pulled off, they’d all give you pretty much the same answer: Deterministic Simulation Testing. They had simply figured out how to test well.
DST is one of the most profoundly transformative pieces of technology developed over the past decade. It is responsible for an exponential speedup in how we test systems for correctness and performance, which is having a cascading effect on how quickly startups can build even the most complex of systems. DST is now standard practice at AWS and countless startups: for example, enabling TigerBeetle to become Jepsen-passing in just 3 years.
And yet, this incredible thing is somehow still underdiscussed and surprisingly poorly documented. This post – alongside the noble work being done down south by Antithesis – will attempt to rectify that. I’m going to go through what DST is, how it was developed, how it works, and how you can get started with it yourself.
- Testing, the true Sisyphean task of programming
- Building a deterministic environment for your code (single threaded pseudo concurrently, simulated implementation of failures, deterministic code)
- OK, but how do you find the bugs?
- Getting started with DST yourself, and a disclaimer
Let’s dive in.
Testing, the true Sisyphean task of programming
Everyone complains that distributed systems are hard to build and debug because they’re complicated. Debugging complicated things is harder than debugging simple things. But the real reason that they’re hard to build is that they’re non-deterministic (and also because they’re complicated). There are simply too many factors out of your control to properly test and debug.
Allow me to illustrate. Imagine you’ve got two servers, and one (Server A) is sending a packet to another (Server B). Any readers who have spent time building distsys can count the number of ways in which even such a simple operation as this can go wrong. One common one is network problems. The packet gets stuck between the two servers, so Server A decides to re-send a new packet…only for the stuck packet to finally get unstuck. Now Server B has duplicated data.
.webp)
This particular bug is easy enough to fix in isolation, save for an important caveat: it’s non-deterministic. You might run this whole scenario again to debug, and nothing happens. The network performs perfectly, as it does 99% of the time. In fact, you might have never found it in the first place because the network worked when you tested it. Even if you found it, you might be unable to reproduce it. And even if you reproduced it, you might be unable to verify that you fixed it.
Whether it’s disk, network, OS, or any other of these kinds of non-deterministic bugs, you are in a pickle: things failing because of conditions outside of your code breaks our mental model of testing. The messy, dirty universe intrudes upon our world of pristine functions and introduces a source of randomness. And this is precisely why it takes so long to build foundational pieces of technology: you and your team essentially need to find as many of these bugs as you can manually. Or do you?
Engineers are smart and know that the litany of unit, integration, and other tests that verify their code itself are limited. They only test for the things you know can go wrong with your code, not the things that can go wrong with your code.
.webp)
This is why there has been a fairly long history of attempts at solving the non-deterministic problem. One old school one that’s seeing a bit of resurgence these days (thanks to AI agents writing code) is Formal Verification. To formally verify, an engineer will model their functions using mathematical precision and logical theorems. You can then be absolutely sure, mathematically sure, that your function will always act as expected (at least for the functions you were able to model).
Formal methods, when you boil them down, are essentially a copy of your code that you test. They’re also generally an incomplete copy, both because of state space explosion and bugs in / misunderstandings of your original code. And that’s likely why none of them ended up becoming the default for testing. When you simulate your code, you end up just testing the simulation, not your code; to say nothing about how incredibly labor intensive it is to build in the first place.
As far as I can tell around the same time but completely independently, Amazon and the FoundationDB team came up with a similar idea…what if your code was your simulation?
Building a deterministic environment for your code
The core of DST is very simple. Instead of building a model of your code – which is difficult and kind of misses the point – we’re just going to take your real code, and make it into the model.
This idea is, of course, insane. We are talking about not just simulating a process in your code, but an entire network of processes, plus all of their interactions with the environment like disks, operating systems, and network. And to build it the FoundationDB team needed to solve 3 pretty gnarly problems.
1) Single threaded pseudo-concurrency
Any particular simulation needs to run in a single process, because if things were actually concurrent you’d be introducing non-determinism. And yet of course within said process, you need to be simulating concurrency, especially if you’re building and testing a distributed system. This turns out to be either very hard or not very hard to implement depending on which programming language you are working in.
Here is a little more color from Phil Eaton’s great post about DST:
Some languages like Go are entirely built around transparent multi-threading and blocking IO. Polar Signals solved this for DST by compiling their application to WASM where it would run on a single thread. But that wasn't enough. Even on a single thread, the Go runtime intentionally schedules goroutines randomly. So Polar Signals forked the Go runtime to control this randomness with an environment variable. That's kind of crazy. Resonate took another approach that also looks cumbersome. I'm not going to attempt to describe it. Go seems like a difficult choice of a language if you want to do DST.
The FoundationDB team decided to use C++ for a few reasons. C++ is, of course, fast, but it is not well suited for the purpose of simulating concurrency. So the team built Flow, a syntactic extension to C++ that allows you to model concurrency while the actual implementation under the hood is all single-threaded (using callbacks).
2) Simulated implementations of your program’s interactions with the world
With DST, all of the randomness and entropy in your program is randomness and entropy that you put there on purpose.
Let’s use a network connection as an example. With DST, instead of making an actual network connection you make a simulated one. The simulated connection is just like a real one: it can wait a bit to simulate latency, copy some bytes from here to there, and do other things that a “real” network connection would do. But unlike a real network connection there is a chance on every execution that any number of pre-programmed things can go wrong: your peer closes the connection, a random error is introduced (you don’t know exactly what happened), etc. How foolish to assume the network is reliable!
This same simulation needs to exist for all of the interactions your program can have with the physical world outside of the network: disk, OS, and even data center.
3) Your code itself needs to be deterministic
Most developers would say their code is deterministic, but:
- Do you ever have a random number involved in your program?
- Do you check the time in an if statement?
- Do you check how much disk space you have free?
If so, your program is non-deterministic, and running it twice could produce two completely different outcomes. For DST to work, your program must be deterministic just like the environment it’s running in.
This is fixable, but takes some effort. In the random number example, to make your program deterministic, you’d need to make sure that your random number actually comes from a pseudo random number generator that you control and you seeded, and that the seed becomes part of the input in the program. The same is true for time. All randomness in your code must come from the same seed that you can track and plug in again for a subsequent run.
OK, but how do you find the bugs?
A completely deterministic simulation is like the most pristine, no-expense-spared tool kit. The tools themselves can only take you so far, it is what you do with them that is most important. It is also tricky to make sure you are actually running all of your most important code in your tests; there are both normal software engineering problems and tricky math problems here.
FoundationDB’s approach to using the tools is encapsulated in something they called test files. A test file looks kind of like a series of config blocks. Perhaps you wanted to randomly clog the network:
testName=Cycle
transactionsPerSecond=1000.0
testDuration=30.0
expectedRate=0.01
testName=RandomClogging
testDuration=30.0
swizzle=1The test file declares a set of stuff that the system is going to try to achieve (in our case, TPS) and then a set of stuff that’s going to prevent it from achieving that (in our case, random clogging). Swizzling, by the way, is when you stop a subset of network connections on a rolling basis and then bring them back up in reverse or random order. For reasons we don’t entirely understand, this is better at finding bugs than normal clogging.
FoundationDB designed primitives for all different kinds of tests. There are tests for broken machines, full data center failures, and even common sysadmin mistakes. But the real power is when you combine multiple of these tests into a single test file:
testName=Cycle
transactionsPerSecond=1000.0
testDuration=30.0
expectedRate=0.01
testName=RandomClogging
testDuration=30.0
swizzle=1
testName=Attrition
machinesToKill=10
machinesToLeave=3
reboot=true
testDuration=30.0
testName=ChangeConfig
maxDelayBeforeChange=30.0
coordinators=autoIn this case your database is going to try to run 1K TPS while dealing with random clogging, dead machines, and config changes…good luck!
“One of the most fun parts of my job is thinking up new and creative ways to torture our database.” -
– Will Wilson, Antithesis cofounder and former FoundationDB engineer
You can start to see how quickly a framework like this is going to uncover bugs that would take years of customer experience to uncover in the wild. Speaking of which…
A DST system is only as valuable as it is fast. Your customers can also be thought of as randomly injecting faults into your code that you will eventually uncover and fix. DST is only useful if it does so at a dramatically faster rate, and there are a few ways to make sure that happens:
- Make failures happen more often. In the real world, a disk might fail every 2-3 years. With DST, you can make it happen every two minutes. You can also literally speed up time and make many more simulated world seconds pass than real world seconds.
- Buggification: you can simply add bugs to your code. The logic would look something like “if in buggify mode” send something in the wrong order, never send a timeout, things like that.
Beyond just brute speedup force, you can also make clever use of the Hurst Exponent. In the 1950’s, a hydrologist (this is a water expert) named Harris Hurst was trying to figure out how to model the Nile River so that architects could build a correctly sized reservoir system. He intuited that weather events leading to swells in the river – namely rain – were not statistically independent, despite the fact that most prevailing models of the day assumed they were. Eventually, a statistical measure of this correlation – essentially the long term memory of a time series – was coined as the Hurst Exponent.
So what does this have to do with distributed systems? Hardware failures are, like the rain beating on the surface of the Nile, not random independent events. If a hard drive fails in a rack, the first thing you do is check every other hard drive in that rack; it could have been a bad batch, there could be a humidity problem in the data center, there could be a power issue, etc. With manual testing it’s almost impossible to test for cascading failures like this. With DST it’s absolutely possible, and FoundationDB manipulated the Hurst Exponent quite a bit to make sure that their database ran up against exactly such clusters of failures.
When you put all of this together, you end up with many more real world hours per hour of simulation. The FoundationDB team ran trillions of real world hours of tests in theirs, routinely racking up 5-10M simulation hours per night. TigerBeetle’s largest of its kind DST cluster – running on 1,000 CPU cores 24x7x365 – goes through 2 millennia of simulated runtime per day.
DST will not fix him
At this point it would be judicious to mention that DST is not a silver bullet, it does not completely protect you from bugs, and it is not without its limitations:
- Your code most likely relies on external systems, which no amount of DST is going to make bug free (unless you convince them to use it??).
- A simulator is only as good as your ability to use it well, and it’s very difficult and time consuming to design test suites that really push your code to the limit.
- DST takes time and compute, it’s not free (literally or temporally).
But, you know, it’s still pretty great.
DST-as-a-service and the Antithesis story
DST was a revelation for the FoundationDB team. It gave them the ability to find all of the bugs in their database. I know this sounds ridiculous, but it was (at least mostly) literally true – in the history of the company, they only had 1 or 2 bugs reported by a customer. Even Kyle Kingsbury didn’t bother Jepsen testing it because, well, he didn’t think he’d find much.
It’s nice to have software without bugs, yes. But the more important takeaway is that this type of testing completely changes how you write code in the first place.
Once you’ve found all the bugs in something, and you have very powerful tests which can find any new ones, programming feels completely different. I’ve only gotten to do this a few times in my career, and it’s hard to convey the feeling in words, but I have to try. It’s like being half of a cyborg, or having a jetpack, or something. You write code, and then you ask the computer if the code is correct, and if not then you try again. Can you imagine having a genie, or an oracle, which just tells you whether you did something wrong?
This is like some sort of drug, and once you experience it it’s really hard to go back to life without it. So much so that after the FoundationDB team dispersed to various tech companies after the acquisition, they were shocked to find that nothing like DST existed at even the most sophisticated of engineering organizations. So in 2018, Dave Scherer and Will Wilson (FoundationDB engineer) started Antithesis. The mission is to bring DST to the masses.
This mission is important because it’s actually quite hard to get started with DST yourself in 2025. You can build a basic toy sandbox, but if you are serious about getting DST into your production loop, we are talking about several months of engineering time. This in turn is part of why it took Antithesis 5 years to get out of stealth: building a deterministic hypervisor is a lot of work.
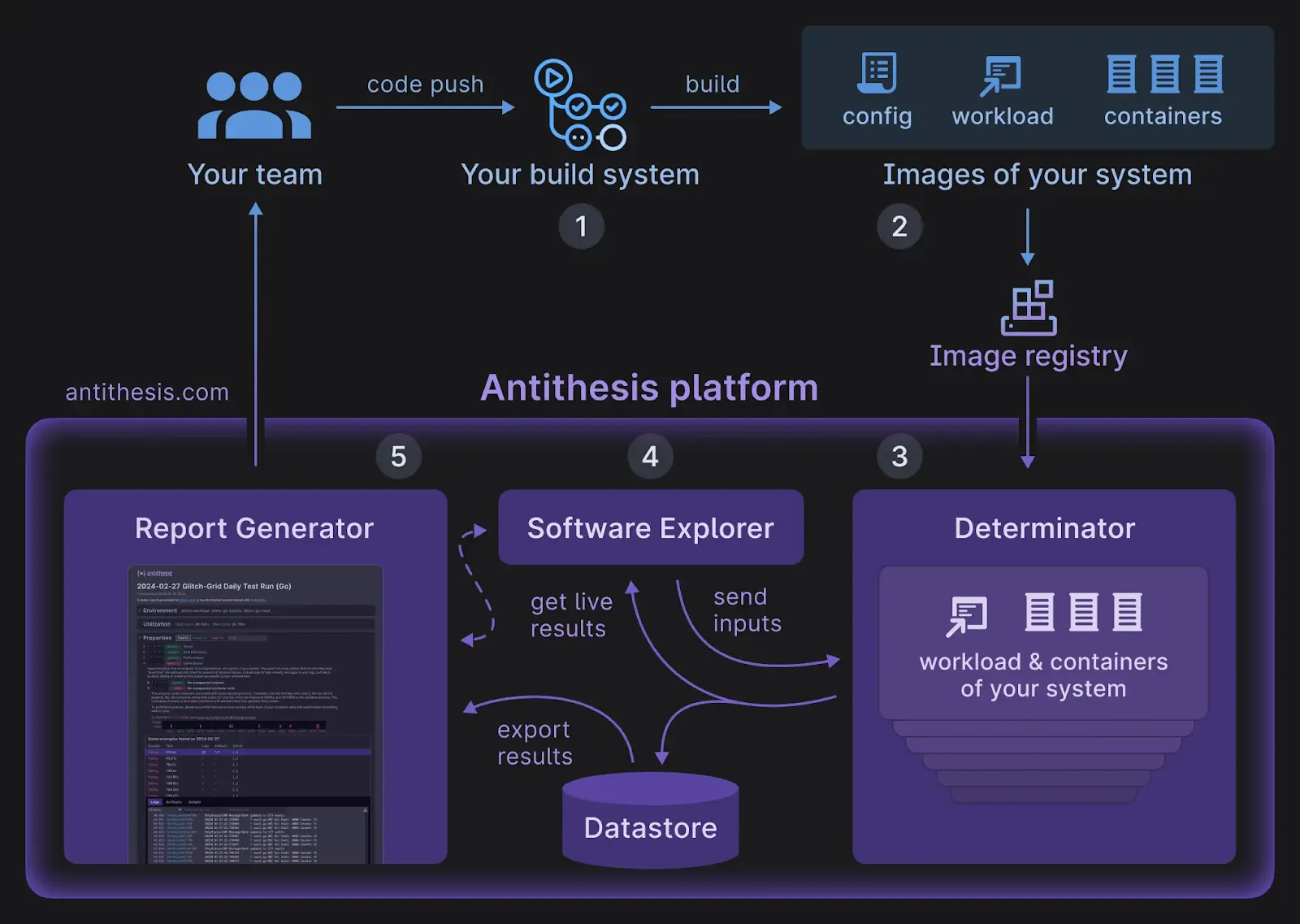
Antithesis is generally available now and I can say without hesitation that it’s the easiest and most foolproof way to make your code bug free. Confluent, MongoDB, Ramp, Palantir, and Ethereum have used them to implement DST and ship bug free code faster. It’s not the kind of thing that you can just sign up for and use, for several obvious reasons. But it’s not exactly hard to get in touch either. In my many years of working on marketing for technical tools, Antithesis is the first company I’ve seen publish specific information on their POC process:
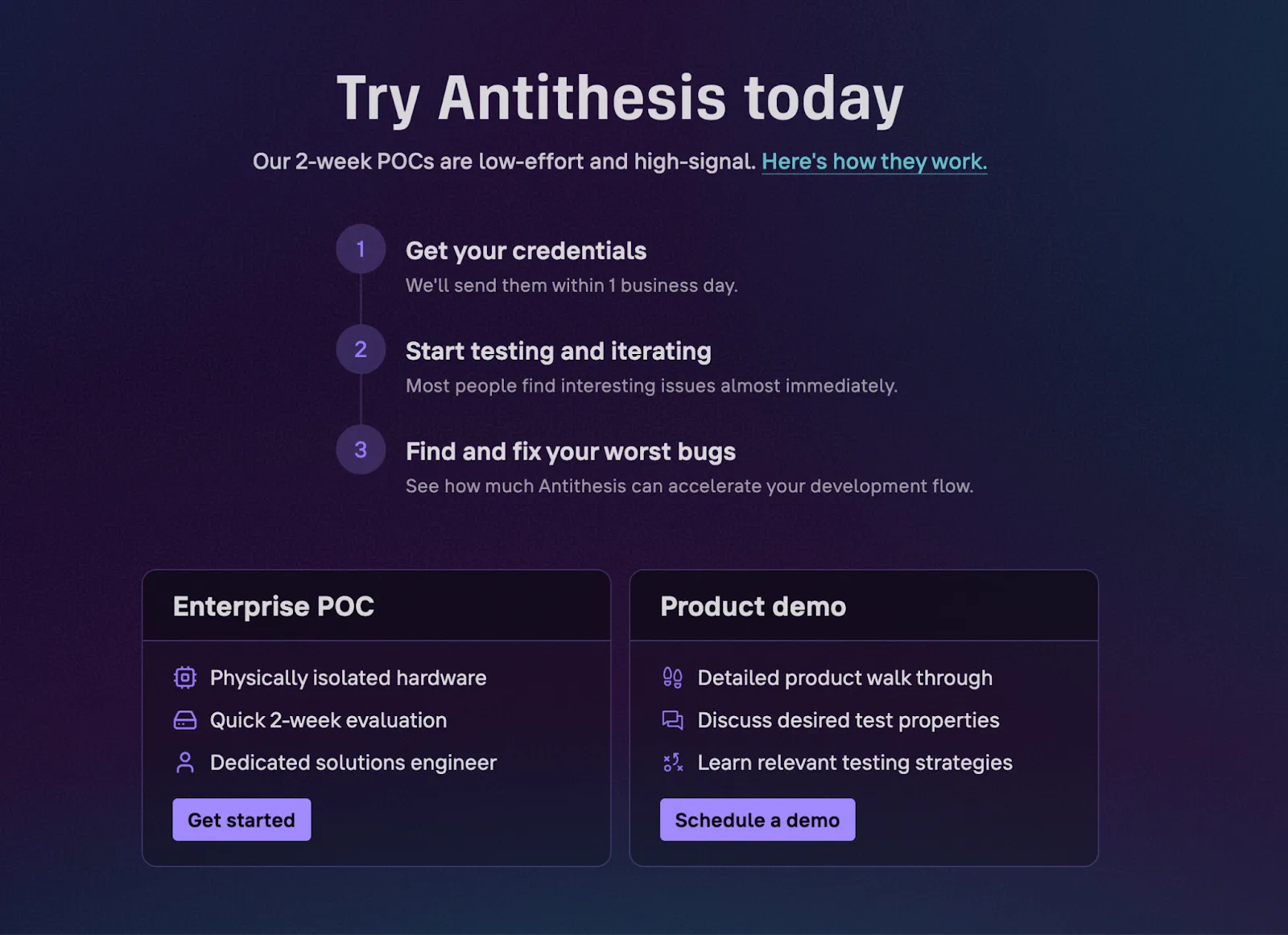
You can book a demo at your leisure. And if you do, tell them Justin at Amplify says hi.





