NeurIPS 2025 Recap
Every year, thousands of pilgrims descend on a holy site for a week of reflection. They share interpretations of sacred scripture, debate the divine’s next revelatory moment and, while seemingly directing their prayer towards a mysterious black box, attain something much higher along the way.
I am of course talking about NeurIPS 2025 in San Diego, although you’ll be forgiven for thinking I was talking about the city’s more hallowed Comic-Con.
Amplify turned up the NeurIPS tempo for its busiest ever year. We hosted two dinners spanning core research and the intersection of biology and AI, as well as two thematic breakfasts on Continual Learning and Memory and AI for Science. We also racked up an egregious step count that left Achilles tendons in sore shape! In this blogpost, we distill some of our nicher conference takeaways.
Ideas for Scaling Environment Design
In the last year, startups and data vendors have emerged that manually create reinforcement learning environments for frontier AI labs. This has become extremely valuable because foundation models require well defined state, action, and reward spaces across code, math, computer-use, and natural language during post-training to learn new behaviors. However, manual design is a costly endeavor and limits agents to interacting with human interpretable environments; and thus the range of skills they can acquire. At NeurIPS, we saw new research that automates such task creation and consequently can massively scale post-training.
In “Self-Challenging Language Model Agents” by Zhou et al., they propose a two role loop where a challenger agent explores its environment and creates a task, and an executor agent trains on that task with RL. They use a structured format called Code as Task consisting of a natural language instruction, code verification function for success, an example solution that passes the verifier, and example failure cases that don’t. By co-creating these unit-tests with the task, it ensures that ambiguous, infeasible, or unverifiable tasks are not generated. By exclusively training on self-generated synthetic data across four tool use environments, the authors beat existing baselines and significantly increased reliability during training.
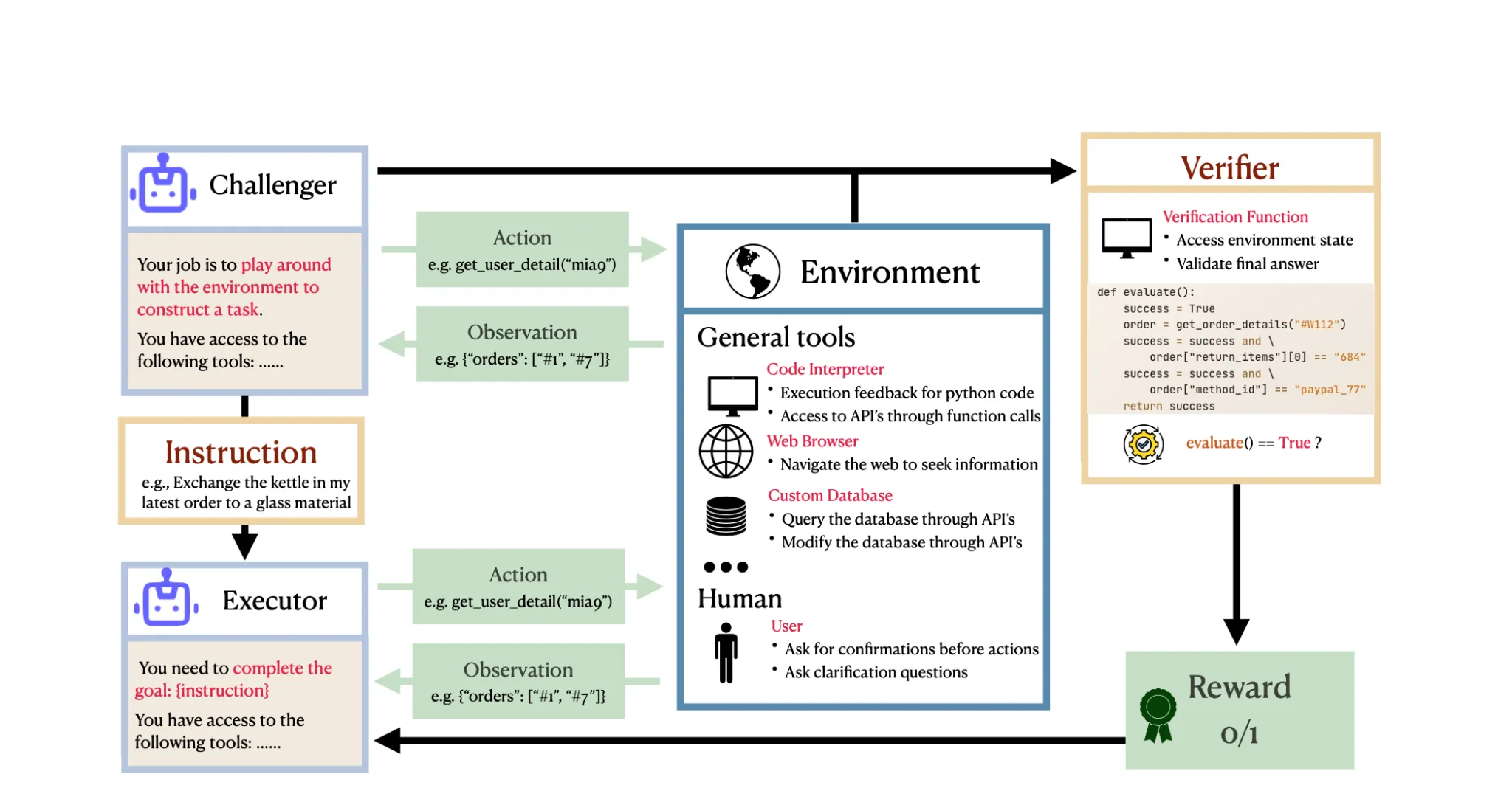
In the Scaling Environments for Agents workshop, Ed Grefenstette went further and gave a talk suggesting ideas like unsupervised environment design combined with LLMs might be sufficient for getting self-play and automated task creation to work throughout training. However, he also added some caveats and important further research questions. Firstly, he claimed that while we want agents to formulate their own reward conditions that humans can read and understand (as in Zhou’s paper), agents should also be able to specify their own objectives that humans don’t understand. On the flipside, he suggested we should seek inspiration from how human agency discovers goals and lean on frameworks like Dual Inheritance Theory as a starting point, asking ourselves “what a functional analogue in the construction and training of our agents would be”.
Multi-Agent Framework Failure and Evolution
Today, most teams need to explicitly specify how agents are constructed and frameworks for how they connect to each other to accomplish goals. While in the last two years we have stumbled upon several helpful design frameworks that have become broadly adopted (such as LLM as a Judge) there has yet to be a systematic analysis of how different frameworks affect performance. There is no “science” behind agent design for any given problem, so we are still stuck in the era of human crafted frameworks.
Rosser and Foerster published AgentBreeder, an evolutionary search over multi-agent frameworks that generates a population of different scaffolds and then selects and mutates them based on performance against an objective. Team structures, role prompts, communication patterns, tool routing, voting strategies and many more variables can be tweaked and it provides a convenient way to spend compute at test-time to improve accuracy. They demonstrate that more agents doesn’t improve performance linearly, but the right protocol can dramatically shift the asymptotic performance ceiling. Moreover, their framework has three modes, trading off optimizing for capability and safety, underlining the importance of maximizing performance without increasing jailbreaking and other unwarranted behavior.
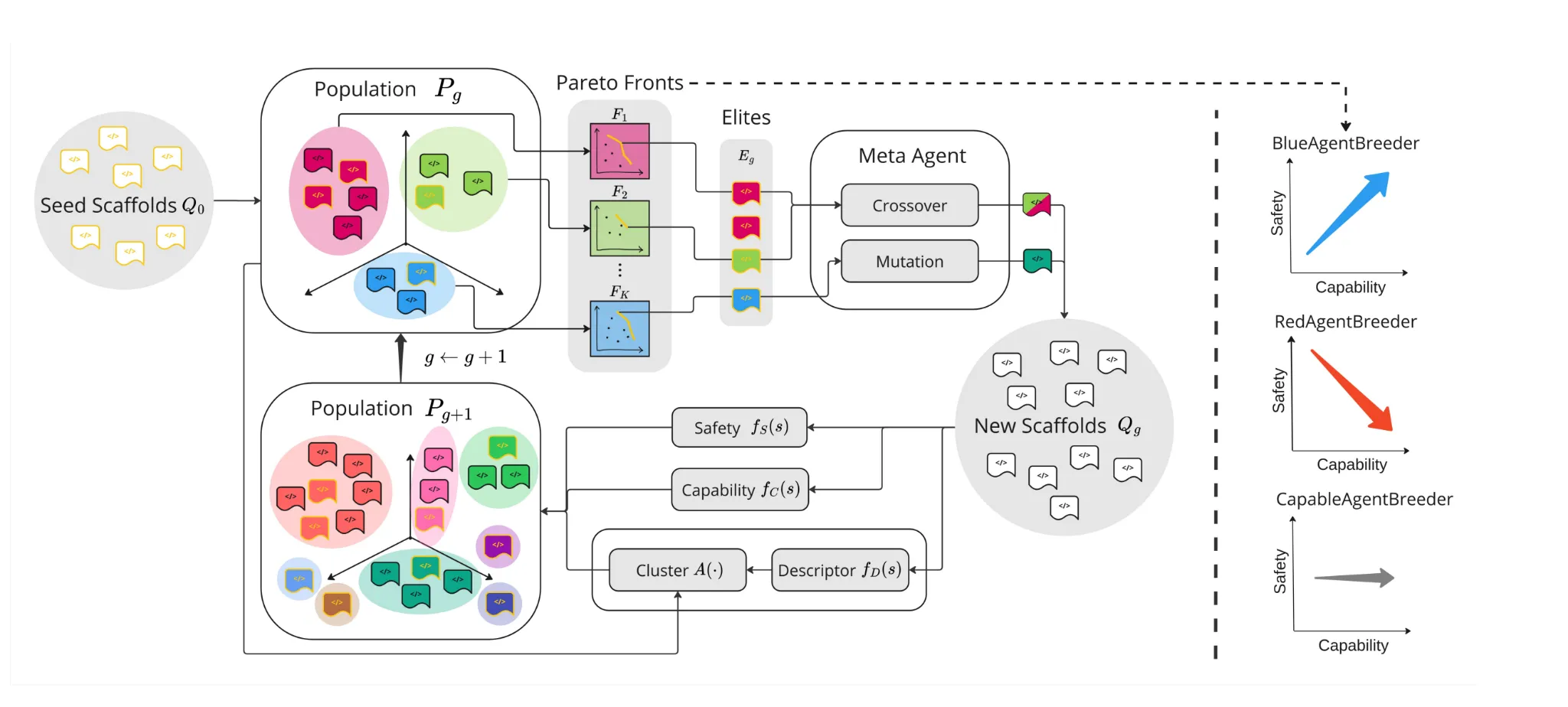
While evolutionary frameworks push the boundaries of what scaffolds can do, we are yet to understand and diagnose common failure modes of these systems to provide a reliable feedback signal for mutation and self-improvement. Cemri, Pan, and Yang et al. released “Why Do Multi-agent Systems Fail” which creates three broad categories for multi-agent failures, using analysis from over 200 execution traces across 7 popular multi-agent frameworks:
- Firstly, we get specification issues: issues in organization ranging from lost conversation histories to disobeying task roles, reflecting that better state management and task aware orchestration and critical.
- Secondly, we get inter-agent misalignment: when agents fail to ask each other clarifying questions, get derailed from tasks or withhold information from each other.
- Finally, we get quality control failures from tasks verification and termination: where systems stop too early, don’t verify at all or incorrectly, so specific success criteria and even uncertainty aware stopping rules may be necessary.
Understanding and Extending Transformer Context
Since the release of ChatGPT, context lengths have exploded from 16K to 1M tokens. As memory, session histories, and multimodal data grows, context lengths will need to grow further. While the transformer has remained relatively untouched since its 2017 debut, we saw sparks of new architectural work and case studies for why it may need updating in a world of complex use cases and long running agents.
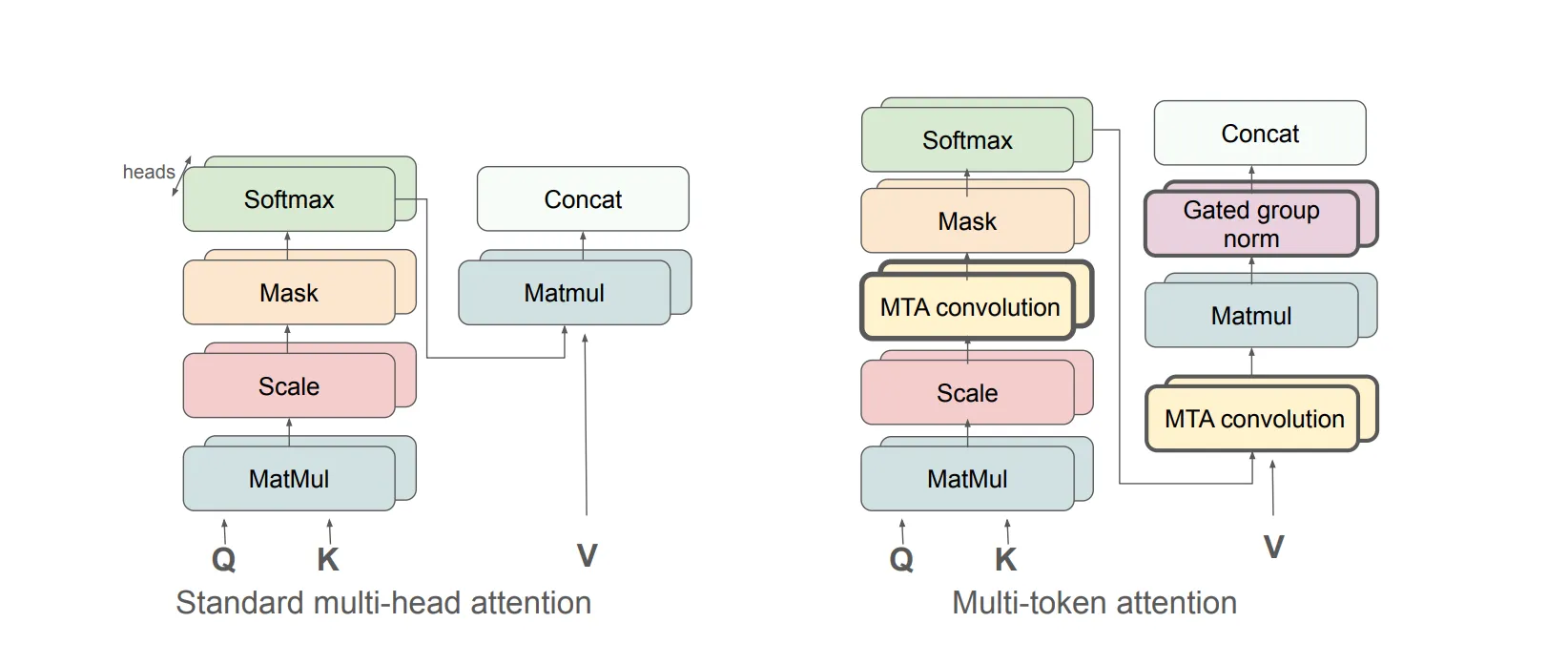
Jason Weston gave a workshop talk highlighting the “Multi-Token Attention” paper for improving long context information handling. Several tasks need multi-token cues, such as “find the sentence where Harry found the Philosopher’s Stone”. This requires taking multiple tokens, such as “Mirror”, “Erised”, “stone” and “pocket”, and squeezing them with standard attention into a single query vector very early in the network layers. This forces the model to pack a lot of information into one place, which limits how well it can search through long text.
The new idea in the paper is to change how attention measures similarity. Instead of asking: “How similar is this token to that token?” (using a dot product between one query and one key), they apply small convolutions around each token before computing attention. That means attention is now comparing short phrases (small windows of tokens), not isolated tokens. So the question becomes: “How similar is a short phrase around this position to a short phrase around another position?” This improves normal metrics like perplexity scores and needle in a haystack problems like finding weird and singular sentences in Harry Potter and the Philosopher’s Stone.
While not a new solution, a bizarre and fascinating instance of transformer malfunction surfaced in AbsenceBench which I am compelled to share. Unlike the needle in the haystack problem for when transformers can’t find an instance of something, this paper flips the script and asks if they can identify what’s missing from a portion of text. Given an original document and a modified document with some words removed, the model is asked to identify what the missing words are. Shockingly, it is unable to do so, despite having the ground truth answer within its own context! Failures across poetry, numerical sequences, and code pull requests suggest attention can’t look at a gap with no token and in fact, longer context worsens task performance. Much work remains for understanding the inner minds of these mystery machines!
Test Time Training and Continual Learning
Since (and before) Ilya Sustskever’s recent appearance on the Dwarkesh podcast, continual learning has tripped off the tongue of almost every researcher in the world. Early work with foundation models explored continual pre-training techniques to efficiently reuse previous model generations rather than train from scratch. Going forward, agents that efficiently adapt at inference time to novel environments will require new research and could potentially be the next paradigm shift beyond scaling model post-training with reinforcement learning. We highlight two papers on these topics below.
In “Self Adapting Language Models” by Zweiger and Pari et al., the authors meta-learn an approach for test-time training using RL so that the model can adapt to new tasks at inference time. Let’s break that down.
Firstly, when the model faces a new task, it creates its own training setup. It generates synthetic training data, hyperparameters and configs, and chooses how to do test-time training on that task (usually using LORA). Then given a set of such training setups, each one is treated as an action the model could choose. Using reinforcement learning, the model tries different actions (setups) and learns which strategy leads to the best performance. This creates an inner and outer loop of training. The inner loop is the model performing test-time training with one of its strategies. The outer loop is using RL to improve how the model generates and selects strategies in the first place. Consequently, the model can learn how to optimally adapt to new data at inference time.

This is particularly interesting as it's a marked shift from previous test-time training methods that have hard-coded rules for how the model should update on new data – now the model has meta-learned the update.
In the Workshop on Continual and Compatible Foundation Model Updates, “Continual pre-training of MOEs” shed light on strategies for updating models with a mixture of experts architecture. When performing continued training on a new domain, it’s possible that experts may become unbalanced, overused, or forget how to handle a previous task. This paper demonstrated that with the right data recipes for reusing old data and re-warming/decaying learning rates, it’s possible to retain and improve upon previous model performance leading to significant efficiency gains. Specifically, with 30-40% previous data replayed, the method reaches within 1% of full retraining performance. Interestingly, they found forgetting is actually slightly less than in full retraining because mixture of experts increases parameter capacity for absorbing new domains and information.
Reinforcement Learning with Multi-Turn Interaction
Today’s reasoning models are trained to take multiple actions to generate one long answer which is rewarded at the very end, forming an incredible answer machine. However, they do not typically ask clarifying questions or fix mistakes when a user pushes back. This would elicit critical human domain knowledge and thus better performance and user-alignment. At the conference, we saw brilliant new work that trains language models across long conversational and environmental interactions, ushering in a more personalized age of foundation models.
In the Workshop on Multi-Turn Interactions with LLMs, Natasha Jaques talked about "Consistently Simulating Human Personas with Multi Turn Reinforcement Learning” which creates faithful synthetic data for such interactive training. Language models are used to simulate humans when training language models but can sometimes change their mood, forget background, or contradict themselves during a long conversation. This weakens the main agent’s training with noisy and unreliable data. They score consistency and accuracy of LLM personas with LLM as a judge, and see over 55% reduction in unfaithfulness across all tasks. As foundation models are used to simulate not just humans but teams and organizations, better evaluation and synthetic data for multi-turn training is critical research.
Finally, “Improving Agent Reasoning by Scaling Test Time Interaction” demonstrated how multi-turn RL is useful in web environments where “interaction” now means tool-use rather than chatting to a human (although going forward could easily mean both!). Instead of simply planning a long sequence of actions given a prompt, the authors progressively increase allowed environment interactions like page visits and clicks to enable exploring and backtracking before reaching a final answer. By treating the number of interactions as part of the learning problem rather than a fixed number, they showcase agents that re-plan mid episode when they’ve made a mistake and try diverse alternative actions. Impressive results on WebArena and WebVoyager beckon an exciting future for how we can spend compute on even more dimensions.
Signing Off
We thoroughly enjoyed our time at NeurIPS and more broadly, our time at several ML conferences across 2025. Understanding the latest research and how it might shape our field is not only important to us, it’s what we find fun. In 2026, you can expect to see us back on the front lines of week long marathons like NeurIPS in Sydney, as well as domain focused, day long workshops that fit intimately in a single lecture theatre (our marketing guy wrote this). We hope you have a lovely holiday season and we’ll see you in the new year for both more of the same and, hopefully, something entirely new!